issues
2,892 rows sorted by updated_at
This data as json, CSV (advanced)
| id | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at ▼ | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 277589569 | MDU6SXNzdWUyNzc1ODk1Njk= | 155 | A primary key column that has foreign key restriction associated won't rendering label column | wsxiaoys 388154 | closed | 0 | Custom templates edition 2949431 | 4 | 2017-11-29T00:40:02Z | 2017-12-07T05:39:53Z | 2017-12-07T05:39:53Z | NONE | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/155/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 278190981 | MDU6SXNzdWUyNzgxOTA5ODE= | 158 | Ensure default templates are designed to be extended | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 1 | 2017-11-30T16:46:41Z | 2017-12-07T05:41:09Z | 2017-12-07T05:41:08Z | OWNER | Since custom templates can do `{% extends "default:table.html" %}` the default templates should include sensible named `{% block %}` components designed to support common extension patterns. Since we already support `{{ super() }}` we may not have much if anything to add here. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/158/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 278191223 | MDU6SXNzdWUyNzgxOTEyMjM= | 159 | Come up with an elegant mechanism for per-row template customization | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 0 | 2017-11-30T16:47:26Z | 2017-12-07T06:12:27Z | 2017-12-07T06:12:26Z | OWNER | It would be nice if customizing the display of an individual row in a custom table template was as simple as possible - refs #153 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/159/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 280014287 | MDU6SXNzdWUyODAwMTQyODc= | 165 | metadata.json support for per-database and per-table information | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 2 | 2017-12-07T06:15:34Z | 2017-12-07T16:48:34Z | 2017-12-07T16:47:29Z | OWNER | Every database and every table should be able to support the following optional metadata: title description description_html license license_url source source_url If `description_html` is provided it over-rides `description` and will be displayed unescaped. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/165/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 275166078 | MDU6SXNzdWUyNzUxNjYwNzg= | 130 | Rename "datasette build" to "datasette inspect" | simonw 9599 | closed | 0 | 0 | 2017-11-19T15:08:02Z | 2017-12-07T16:57:58Z | 2017-12-07T16:57:58Z | OWNER | This command introspects the databases and writes out a JSON summary. I think I'd like to use `datasette build` for something more interesting, potentially duplicating functionality from https://github.com/simonw/csvs-to-sqlite Since the internal method that does this is called `ds.inspect()` that seems like a reasonable replacement name for the command. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/130/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 280023225 | MDU6SXNzdWUyODAwMjMyMjU= | 166 | Documentation for metadata.json and datasette skeleton | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 1 | 2017-12-07T07:02:52Z | 2017-12-07T17:20:35Z | 2017-12-07T17:20:25Z | OWNER | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/166/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 278814220 | MDU6SXNzdWUyNzg4MTQyMjA= | 161 | Support WITH query | wsxiaoys 388154 | closed | 0 | 4 | 2017-12-03T20:00:40Z | 2017-12-08T06:18:12Z | 2017-12-04T04:52:41Z | NONE | Currently datasettle failed with error message: Statement must begin with SELECT Example query ```sql WITH RECURSIVE cnt(x) AS ( SELECT 1 UNION ALL SELECT x+1 FROM cnt LIMIT 1000000 ) SELECT x FROM cnt; ``` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/161/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 280662866 | MDExOlB1bGxSZXF1ZXN0MTU3MzY1ODEx | 168 | Upgrade to Sanic 0.7.0 | simonw 9599 | closed | 0 | 1 | 2017-12-09T01:25:08Z | 2017-12-09T03:00:34Z | 2017-12-09T03:00:34Z | OWNER | simonw/datasette/pulls/168 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/168/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | ||||||
| 276873891 | MDU6SXNzdWUyNzY4NzM4OTE= | 154 | Datasette CSS should include content hash in the URL | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 3 | 2017-11-27T00:57:36Z | 2017-12-09T03:10:23Z | 2017-12-09T03:10:22Z | OWNER | When I deployed the latest version of datasette to https://fivethirtyeight.datasettes.com/ I noticed I was getting served stale CSS since it had been cached. Including the sha of he contents in its URL should fix that. I can calculate this on server start. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/154/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 280745470 | MDU6SXNzdWUyODA3NDU0NzA= | 170 | Custom template for named canned query | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 3 | 2017-12-09T19:07:51Z | 2017-12-09T21:35:30Z | 2017-12-09T21:34:52Z | OWNER | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/170/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 280745746 | MDU6SXNzdWUyODA3NDU3NDY= | 171 | HTML comments specifying custom templates for page | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 1 | 2017-12-09T19:11:13Z | 2017-12-09T21:50:50Z | 2017-12-09T21:48:03Z | OWNER | This would make the custom templating system self-documenting, and save people from having to figure out the right template names for customizing specific pages. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/171/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 280315352 | MDU6SXNzdWUyODAzMTUzNTI= | 167 | Nasty bug: last column not being correctly displayed | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 6 | 2017-12-07T23:23:46Z | 2017-12-10T01:00:21Z | 2017-12-10T01:00:20Z | OWNER | e.g. https://datasette-bwnojrhmmg.now.sh/dk3-bde9a9a/dk?source__contains=http  The JSON output shows that the column is there, but is being displayed incorrectly: https://datasette-bwnojrhmmg.now.sh/dk3-bde9a9a/dk.jsono?source__contains=http  | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/167/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 280744309 | MDU6SXNzdWUyODA3NDQzMDk= | 169 | Release v0.14 with templates and static files features | simonw 9599 | closed | 0 | Custom templates edition 2949431 | 1 | 2017-12-09T18:52:48Z | 2017-12-10T02:04:56Z | 2017-12-10T02:04:56Z | OWNER | Everything in this milestone https://github.com/simonw/datasette/milestone/6 - plus various other fixes: https://github.com/simonw/datasette/compare/0.13...6bdfcf60760c27e29ff34692d06e62b36aeecc56 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/169/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 276842536 | MDU6SXNzdWUyNzY4NDI1MzY= | 153 | Ability to customize presentation of specific columns in HTML view | ftrain 20264 | closed | 0 | Custom templates edition 2949431 | 14 | 2017-11-26T17:46:11Z | 2017-12-10T02:08:45Z | 2017-12-07T06:17:33Z | NONE | This ties into https://github.com/simonw/datasette/issues/3 in some ways. It would be great to have some adaptability in the HTML views and to specific some columns as displaying in certain ways. - [x] 1. **Auto-parsing URIs into in-browser links.** Why? Lots of public data around cultural commons stuff links to a specific URL. This would be a great utility to turn on at the command line, just parse everything for URLs. Maybe they need to be underlined or represented in a different way than internal URLs. - [x] 2. **Ability to identify a column as plain/preformatted text.** Why? Was trying to import the Enron emails, the body collapses. Hard to read. These fields also tend to screw up the ability to scan a table view. If you knew it was text the system could set an `overflow` property on the relevant CSS, so you could still scan. - [x] 3. **Ability to identify a column as HTML.** Why? I want to spider some stuff and drop sections into SQLite, and just keep them as HTML. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/153/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 268591332 | MDU6SXNzdWUyNjg1OTEzMzI= | 42 | Homepage UI for editing metadata file | simonw 9599 | closed | 0 | 4 | 2017-10-26T00:22:03Z | 2017-12-10T03:02:14Z | 2017-12-10T03:02:14Z | OWNER | Since we are going to have a metadata file which sets the title/description/etc for each database, why not allow you to run the app in —dev mode which makes the homepage into a WYSIWYG editor that can save to that file format. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/42/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 273026602 | MDU6SXNzdWUyNzMwMjY2MDI= | 52 | Solution for temporarily uploading DB so it can be built by docker | simonw 9599 | closed | 0 | 2 | 2017-11-10T18:55:25Z | 2017-12-10T03:02:57Z | 2017-12-10T03:02:57Z | OWNER | For the `datasette publish` command I ideally need a way of uploading the specified DB to somewhere temporary on the internet so that when the Dockerfile is built by the final hosting location it can download that database as part of the build process. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/52/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 273846123 | MDU6SXNzdWUyNzM4NDYxMjM= | 90 | datasette publish heroku | simonw 9599 | closed | 0 | 8 | 2017-11-14T16:01:39Z | 2017-12-10T03:06:34Z | 2017-12-10T03:05:48Z | OWNER | Heroku has Docker container support so this should not be too hard: https://devcenter.heroku.com/articles/container-registry-and-runtime See also #59 This should work exactly like the existing “datasette publish now....” command except it would be “datasette publish heroku...” | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/90/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 273878873 | MDU6SXNzdWUyNzM4Nzg4NzM= | 91 | Option to serve databases from a different prefix, serve regular content elsewhere | simonw 9599 | closed | 0 | 1 | 2017-11-14T17:32:46Z | 2017-12-10T03:07:58Z | 2017-12-10T03:07:53Z | OWNER | It would be useful if the databases themselves could be served from a prefix e.g. datasette serve mydb.db --path-prefix=db Now my database is at `http://localhost:8001/db/mydb-23423` This would free up the rest of the URL namespace for other things. Maybe we could have an option to serve static content from a known folder e.g. datasette serve mydb.db --path-prefix=db --root-content=~/my-project/static Now a hit to `http://localhost:8001/news/` serves content from `~/my-project/static/news/index.html` This would make it trivial to package up entire HTML/CSS/JS apps with one or more underlying SQLite databases. Running without `--cors` would be fine here because any JS apps would be hosted on the same origin. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/91/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 275476839 | MDU6SXNzdWUyNzU0NzY4Mzk= | 138 | Per-database and per-table metadata, probably using data-package | simonw 9599 | closed | 0 | 1 | 2017-11-20T19:50:10Z | 2017-12-10T03:08:36Z | 2017-12-10T03:08:26Z | OWNER | Ability to annotate databases and tables with extra metadata describing their purpose, providing source and licensing information and describing individual columns. http://frictionlessdata.io/specs/data-package/ looks like a great format for this, see #105 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/138/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 267515678 | MDU6SXNzdWUyNjc1MTU2Nzg= | 3 | Make individual column valuables addressable, with smart content types | simonw 9599 | open | 0 | 1 | 2017-10-23T01:11:32Z | 2017-12-10T03:11:58Z | OWNER | Some SQLite databases embed images in columns. It would be cool if these had URLs. /database-name-7sha256/table-name/compound-pk/column /database-name-7sha256/table-name/compound-pk/column.json /database-name-7sha256/table-name/compound-pk/column.png /database-name-7sha256/table-name/compound-pk/column.gif /database-name-7sha256/table-name/compound-pk/column.txt The one without an explicit file extension auto-detects the correct extension. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/3/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 268110769 | MDU6SXNzdWUyNjgxMTA3Njk= | 33 | Use locust for benchmarking and load tests | simonw 9599 | open | 0 | 0 | 2017-10-24T17:00:09Z | 2017-12-10T03:12:16Z | OWNER | https://github.com/locustio/locust Needed for #32 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/33/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 282971961 | MDU6SXNzdWUyODI5NzE5NjE= | 175 | Add project topic "automatic-api" | dbohdan 3179832 | closed | 0 | 1 | 2017-12-18T18:09:17Z | 2017-12-21T18:33:55Z | 2017-12-21T18:33:55Z | NONE | Hi there! Could you add the ~~tag~~ topic `automatic-api` to your repository? I am [making a list](https://github.com/dbohdan/automatic-api) of all projects that automatically expose APIs to databases. (Your Show HN made me do it. :-) I knew about PostgREST and PostGraphQL, but it took adding Datasette to sell me on the concept.) They will be easier to discover if there is a standard GitHub tag, and `automatic-api` seems as good a candidate as any. Two projects [already use it](https://github.com/topics/automatic-api). | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/175/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 287240246 | MDExOlB1bGxSZXF1ZXN0MTYxOTgyNzEx | 178 | If metadata exists, add it to heroku launch command | psychemedia 82988 | closed | 0 | 1 | 2018-01-09T21:42:21Z | 2018-01-15T09:42:46Z | 2018-01-14T21:05:16Z | CONTRIBUTOR | simonw/datasette/pulls/178 | The heroku build does seem to make use of any provided `metadata.json` file. Add the `--metadata` switch to the Heroku web launch command if a `metadata.json` file is available. Addresses: https://github.com/simonw/datasette/issues/177 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/178/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 286938589 | MDU6SXNzdWUyODY5Mzg1ODk= | 177 | Publishing to Heroku - metadata file not uploaded? | psychemedia 82988 | closed | 0 | 0 | 2018-01-09T01:04:31Z | 2018-01-25T16:45:32Z | 2018-01-25T16:45:32Z | CONTRIBUTOR | Trying to run *datasette* (version 0.14) on Heroku with a `metadata.json` doesn't seem to be picking up the `metadata.json` file? On a Mac with dodgy `tar` support: ``` ▸ Couldn't detect GNU tar. Builds could fail due to decompression errors ▸ See ▸ https://devcenter.heroku.com/articles/platform-api-deploying-slugs#create-slug-archive ▸ Please install it, or specify the '--tar' option ▸ Falling back to node's built-in compressor ``` Could that be causing the issue? Also, I'm not seeing custom query links anywhere obvious when I run the metadata file with a local *datasette* server? | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/177/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 306811513 | MDU6SXNzdWUzMDY4MTE1MTM= | 186 | proposal new option to disable user agents cache | stefanocudini 47107 | closed | 0 | 3 | 2018-03-20T10:42:20Z | 2018-03-21T09:07:22Z | 2018-03-21T01:28:31Z | NONE | I think it would be very useful for debugging an option of adding headers to http replies ``` Cache-Control: no-cache ``` especially in the html output | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/186/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 309558826 | MDU6SXNzdWUzMDk1NTg4MjY= | 190 | Keyset pagination doesn't work correctly for compound primary keys | simonw 9599 | closed | 0 | 7 | 2018-03-28T22:45:06Z | 2018-03-30T06:31:15Z | 2018-03-30T06:26:28Z | OWNER | Consider https://datasette-issue-190-compound-pks.now.sh/compound-pks-9aafe8f/compound_primary_key  The next= link is to `d,v`: https://datasette-issue-190-compound-pks.now.sh/compound-pks-9aafe8f/compound_primary_key?_next=d%2Cv But that page starts with: 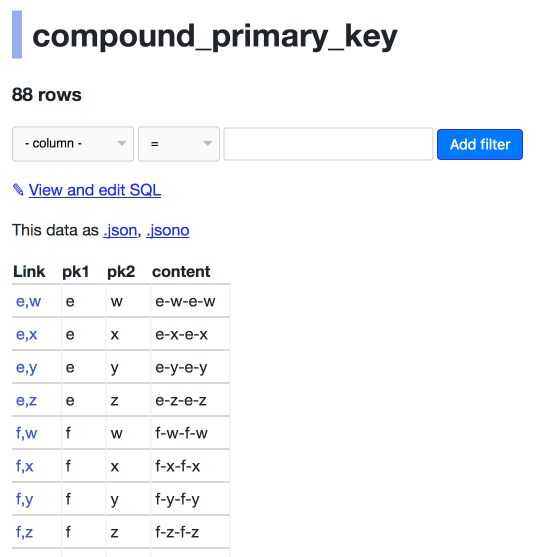 The next key in the sequence should be `d,w`. Also we should return the full a-z of the ones that start with the letter e - in this example we only return `e-w`, `e-x`, `e-y` and `e-z` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/190/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 310850458 | MDExOlB1bGxSZXF1ZXN0MTc5MTA4OTYx | 192 | New ?_shape=objects/object/lists param for JSON API | simonw 9599 | closed | 0 | 0 | 2018-04-03T14:02:58Z | 2018-04-03T14:53:00Z | 2018-04-03T14:52:55Z | OWNER | simonw/datasette/pulls/192 | Refs #122 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/192/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 289375133 | MDExOlB1bGxSZXF1ZXN0MTYzNTIzOTc2 | 180 | make html title more readable in query template | ryanpitts 56477 | closed | 0 | 0 | 2018-01-17T18:56:03Z | 2018-04-03T16:03:38Z | 2018-04-03T15:24:05Z | CONTRIBUTOR | simonw/datasette/pulls/180 | tiny tweak to make this easier to visually parse—I think it matches your style in other templates | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/180/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 275092453 | MDU6SXNzdWUyNzUwOTI0NTM= | 122 | Redesign JSON output, ditch jsono, offer variants controlled by parameter instead | simonw 9599 | closed | 0 | 5 | 2017-11-18T16:52:28Z | 2018-04-08T14:54:09Z | 2018-04-08T14:54:09Z | OWNER | I want to support three variants for the rows output: * a list of lists, with a columns key saying what they are * a list of dictionaries * a single dictionary where the keys are the primary keys of the rows and the values are the row dictionaries themselves I also want to make the various bits of metadata opt-in - so you don't get the SQL statement unless you ask for it. These output options should be controlled by query string arguments. I will set the .jsono URL to redirect to .json with the corresponding options. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/122/reactions", "total_count": 1, "+1": 0, "-1": 0, "laugh": 0, "hooray": 1, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 312355154 | MDExOlB1bGxSZXF1ZXN0MTgwMTg4Mzk3 | 196 | _sort= and _sort_desc= parameters to table view | simonw 9599 | closed | 0 | 0 | 2018-04-09T00:07:21Z | 2018-04-09T05:10:29Z | 2018-04-09T05:10:23Z | OWNER | simonw/datasette/pulls/196 | See #189 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/196/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 312312125 | MDU6SXNzdWUzMTIzMTIxMjU= | 194 | Rename table_rows and filtered_table_rows to have _count suffix | simonw 9599 | closed | 0 | 2 | 2018-04-08T14:53:37Z | 2018-04-09T05:25:22Z | 2018-04-09T05:25:22Z | OWNER | These fields represent counts of items: "table_rows": 131, "filtered_table_rows": 8, But the names make it sound like they might be arrays full of rows. Adding a `_count` suffix would make this more clear: "table_rows_count": 131, "filtered_table_rows_count": 8, | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/194/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 312620566 | MDU6SXNzdWUzMTI2MjA1NjY= | 199 | Ability to apply sort on mobile in portrait mode | simonw 9599 | closed | 0 | 4 | 2018-04-09T17:35:04Z | 2018-04-10T00:37:53Z | 2018-04-10T00:34:38Z | OWNER | Missed this in #189... on mobile in portrait mode we hide the column headers, which means you can't click them to sort! You can sort in landscape mode at least. Need to come up with an alternative sort UI for portrait on mobile. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/199/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 312313496 | MDU6SXNzdWUzMTIzMTM0OTY= | 195 | Run pks_for_table in inspect, executing once at build time rather than constantly | simonw 9599 | closed | 0 | 3 | 2018-04-08T15:12:40Z | 2018-04-10T00:54:43Z | 2018-04-10T00:54:43Z | OWNER | Right now several Datasette views call the `await self.pks_for_table(...)` method to figure out what primary keys are set for a specific table. This executes a `PRAGMA table_info` SQL query. It would be faster and more efficient to execute this query for each table as part of the `inspect()` method. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/195/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 313494458 | MDExOlB1bGxSZXF1ZXN0MTgxMDMzMDI0 | 200 | Hide Spatialite system tables | russss 45057 | closed | 0 | 3 | 2018-04-11T21:26:58Z | 2018-04-12T21:34:48Z | 2018-04-12T21:34:48Z | CONTRIBUTOR | simonw/datasette/pulls/200 | They were getting on my nerves. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/200/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 310882100 | MDU6SXNzdWUzMTA4ODIxMDA= | 193 | Cleaner mechanism for handling custom errors | simonw 9599 | closed | 0 | 3 | 2018-04-03T15:19:13Z | 2018-04-13T18:18:59Z | 2018-04-13T18:18:59Z | OWNER | This code is pretty messy: https://github.com/simonw/datasette/blob/0abd3abacb309a2bd5913a7a2df4e9256585b1bb/datasette/app.py#L245-L265 Instead, it would be nice if I could raise an exception that would be converted into the appropriate JSON or HTML error message, with a corresponding HTTP code. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/193/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 313785206 | MDExOlB1bGxSZXF1ZXN0MTgxMjQ3NTY4 | 202 | Raise 404 on nonexistent table URLs | russss 45057 | closed | 0 | 2 | 2018-04-12T15:47:06Z | 2018-04-13T19:22:56Z | 2018-04-13T18:19:15Z | CONTRIBUTOR | simonw/datasette/pulls/202 | Currently they just 500. Also cleaned the logic up a bit, I hope I didn't miss anything. This is issue #184. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/202/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 313512748 | MDU6SXNzdWUzMTM1MTI3NDg= | 201 | Support explain select / explain query plan select | simonw 9599 | closed | 0 | 1 | 2018-04-11T22:41:26Z | 2018-04-13T21:17:14Z | 2018-04-12T21:32:52Z | OWNER | See https://www.sqlite.org/eqp.html and https://www.sqlite.org/lang_explain.html | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/201/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 314256802 | MDExOlB1bGxSZXF1ZXN0MTgxNjAwOTI2 | 204 | Initial units support | russss 45057 | closed | 0 | 0 | 2018-04-13T21:32:49Z | 2018-04-14T09:44:33Z | 2018-04-14T03:32:54Z | CONTRIBUTOR | simonw/datasette/pulls/204 | Add support for specifying units for a column in metadata.json and rendering them on display using [pint](https://pint.readthedocs.io/en/latest/). Example table metadata: ```json "license_frequency": { "units": { "frequency": "Hz", "channel_width": "Hz", "height": "m", "antenna_height": "m", "azimuth": "degrees" } } ``` [Example result](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency/1) This works surprisingly well! I'd like to add support for using units when querying but this is PR is pretty usable as-is. (Pint doesn't seem to support decibels though - it thinks they're decibytes - which is an annoying omission.) (ref ticket #203) | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/204/reactions", "total_count": 1, "+1": 1, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 314323977 | MDExOlB1bGxSZXF1ZXN0MTgxNjQ0ODA1 | 206 | Fix sqlite error when loading rows with no incoming FKs | russss 45057 | closed | 0 | 0 | 2018-04-14T12:08:17Z | 2018-04-14T14:32:42Z | 2018-04-14T14:24:25Z | CONTRIBUTOR | simonw/datasette/pulls/206 | This fixes `ERROR: conn=<sqlite3.Connection object at 0x10bbb9f10>, sql = 'select ', params = {'id': '1'}` caused by an invalid query loading incoming FKs when none exist. The error was ignored due to async but it still got printed to the console. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/206/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 314329002 | MDExOlB1bGxSZXF1ZXN0MTgxNjQ3NzE3 | 207 | Link foreign keys which don't have labels | russss 45057 | closed | 0 | 1 | 2018-04-14T13:27:14Z | 2018-04-14T15:00:00Z | 2018-04-14T15:00:00Z | CONTRIBUTOR | simonw/datasette/pulls/207 | This renders unlabeled FKs as simple links. I can't see why this would cause any major problems.  Also includes bonus fixes for two minor issues: * In foreign key link hrefs the primary key was escaped using HTML escaping rather than URL escaping. This broke some non-integer PKs. * Print tracebacks to console when handling 500 errors. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/207/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 314319372 | MDExOlB1bGxSZXF1ZXN0MTgxNjQyMTE0 | 205 | Support filtering with units and more | russss 45057 | closed | 0 | 3 | 2018-04-14T10:47:51Z | 2018-04-14T15:24:04Z | 2018-04-14T15:24:04Z | CONTRIBUTOR | simonw/datasette/pulls/205 | The first commit: * Adds units to exported JSON * Adds units key to metadata skeleton * Adds some docs for units The second commit adds filtering by units by the first method I mentioned in #203:  [Try it here](https://wtr-api.herokuapp.com/wtr-663ea99/license_frequency?frequency__gt=50GHz&height__lt=50ft). I think it integrates pretty neatly. The third commit adds support for registering custom units with Pint from metadata.json. Probably pretty niche, but I need decibels! | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/205/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 314340944 | MDExOlB1bGxSZXF1ZXN0MTgxNjU0ODM5 | 208 | Return HTTP 405 on InvalidUsage rather than 500 | russss 45057 | closed | 0 | 0 | 2018-04-14T16:12:50Z | 2018-04-14T18:00:39Z | 2018-04-14T18:00:39Z | CONTRIBUTOR | simonw/datasette/pulls/208 | This also stops it filling up the logs. This happens for HEAD requests at the moment - which perhaps should be handled better, but that's a different issue. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/208/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 309471814 | MDU6SXNzdWUzMDk0NzE4MTQ= | 189 | Ability to sort (and paginate) by column | simonw 9599 | closed | 0 | simonw 9599 | 31 | 2018-03-28T18:04:51Z | 2018-04-15T18:54:22Z | 2018-04-09T05:16:02Z | OWNER | As requested in https://github.com/simonw/datasette/issues/185#issuecomment-376614973 I've previously avoided this for performance reasons: sort-by-column on a column without an index is likely to perform badly for hundreds of thousands of rows. That's not a good enough reason to avoid the feature entirely though. A few options: * Allow sort-by-column by default, give users the option to disable it for specific tables/columns * Disallow sort-by-column by default, give users option (probably in `metadata.json`) to enable it for specific tables/columns * Automatically detect if a column either has an index on it OR a table has less than X rows in it We already have the mechanism in place to cut off SQL queries that take more than X seconds, so if someone DOES try to sort by a column that's too expensive it won't actually hurt anything - but it would be nice to not show people a "sort" option which is guaranteed to throw a timeout error. The vast majority of datasette usage that I've seen so far is on smaller datasets where the performance penalties of sort-by-column are extremely unlikely to show up. ---- Still left to do: - [x] UI that shows which sort order is currently being applied (in HTML and in JSON) - [x] UI for applying a sort order (with rel=nofollow to avoid Google crawling it) - [x] Sort column names should be escaped correctly in generated SQL - [x] Validation that the selected sort order is a valid column - [x] Throw error if user attempts to apply _sort AND _sort_desc at the same time - [x] Ability to disable sorting (or sort only for specific columns) in metadata.json - [x] Fix "201 rows where sorted by sortable_with_nulls " bug | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/189/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 314469126 | MDExOlB1bGxSZXF1ZXN0MTgxNzMxOTU2 | 210 | Start of the plugin system, based on pluggy | simonw 9599 | closed | 0 | 0 | 2018-04-16T00:51:30Z | 2018-04-16T00:56:16Z | 2018-04-16T00:56:16Z | OWNER | simonw/datasette/pulls/210 | Refs #14 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/210/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 314471743 | MDU6SXNzdWUzMTQ0NzE3NDM= | 211 | Load plugins from a `--plugins-dir=plugins/` directory | simonw 9599 | closed | 0 | 6 | 2018-04-16T01:17:43Z | 2018-04-16T05:22:02Z | 2018-04-16T05:22:02Z | OWNER | In #14 and 33c7c53ff87c2 I've added working support for setuptools entry_points plugins. These can be installed from PyPI using `pip install ...`. I imagine some projects will benefit from being able to add plugins without first publishing them to PyPI. Datasette already supports [loading custom templates](http://datasette.readthedocs.io/en/latest/custom_templates.html#custom-templates) like so: datasette serve --template-dir=mytemplates/ mydb.db I propose an additional option, `--plugins-dir=` which specifies a directory full of `blah.py` files which will be loaded into Datasette when the application server starts. datasette serve --plugins-dir=myplugins/ mydb.db This will also need to be supported by `datasette publish` as those Python files should be copied up as part of the deployment. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/211/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 314504812 | MDExOlB1bGxSZXF1ZXN0MTgxNzU1MjIw | 212 | New --plugins-dir=plugins/ option | simonw 9599 | closed | 0 | 0 | 2018-04-16T05:19:28Z | 2018-04-16T05:22:18Z | 2018-04-16T05:22:01Z | OWNER | simonw/datasette/pulls/212 | Refs #211 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/212/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 314506033 | MDU6SXNzdWUzMTQ1MDYwMzM= | 213 | Documentation for plugins system | simonw 9599 | closed | 0 | 0 | 2018-04-16T05:27:07Z | 2018-04-16T15:12:48Z | 2018-04-16T15:12:48Z | OWNER | Documentation for #14 - how to write plugins, how to ship plugins to PyPI and how to use the `--plugins-dir` option added in #211 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/213/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 313837303 | MDU6SXNzdWUzMTM4MzczMDM= | 203 | Support for units | russss 45057 | closed | 0 | 10 | 2018-04-12T18:24:28Z | 2018-04-16T21:59:17Z | 2018-04-16T21:59:17Z | CONTRIBUTOR | It would be nice to be able to attach a unit to a column in the metadata, and have it rendered with that unit (and SI prefix) when it's displayed. It would also be nice to support entering the prefixes in variables when querying. With my radio licensing app I've put all frequencies in Hz. It's easy enough to special-case the row rendering to add the SI prefixes, but it's pretty unusable when querying by that field. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/203/reactions", "total_count": 1, "+1": 1, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 314834783 | MDU6SXNzdWUzMTQ4MzQ3ODM= | 219 | Expose units in the JSON API? | russss 45057 | open | 0 | 0 | 2018-04-16T22:04:25Z | 2018-04-16T22:04:25Z | CONTRIBUTOR | From #203: it would be nice for the JSON API to (optionally) return columns rendered with units in them - if, for example, you're consuming the JSON to render the rows on a map. I'm not entirely sure how useful this will be though - at the moment my map queries are custom SQL queries (a few have joins in, the rest might be fetching large amounts of data so it makes sense to limit columns fetched). Perhaps the SQL function is a better approach in general. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/219/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 314665147 | MDU6SXNzdWUzMTQ2NjUxNDc= | 216 | Bug: Sort by column with NULL in next_page URL | carlmjohnson 222245 | closed | 0 | 15 | 2018-04-16T14:03:18Z | 2018-04-17T01:45:24Z | 2018-04-17T01:45:24Z | NONE | Copy-pasting from https://github.com/simonw/datasette/issues/189#issuecomment-381429213, since that issue is closed: I think I found a bug. I tried to sort by middle initial in my salaries set, and many middle initials are null. The `next_url` gets set by Datasette to: http://localhost:8001/salaries-d3a5631/2017+Maryland+state+salaries?_next=None%2C391&_sort=middle_initial But then None is interpreted literally and it tries to find a name with the middle initial "None" and ends up skipping ahead to O on page 2. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/216/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 315316214 | MDExOlB1bGxSZXF1ZXN0MTgyMzU3NjEz | 222 | Fix for plugins in Python 3.5 | simonw 9599 | closed | 0 | 0 | 2018-04-18T03:21:01Z | 2018-04-18T04:26:50Z | 2018-04-18T03:24:21Z | OWNER | simonw/datasette/pulls/222 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/222/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | ||||||
| 314455877 | MDExOlB1bGxSZXF1ZXN0MTgxNzIzMzAz | 209 | Don't duplicate simple primary keys in the link column | russss 45057 | closed | 0 | 6 | 2018-04-15T21:56:15Z | 2018-04-18T08:40:37Z | 2018-04-18T01:13:04Z | CONTRIBUTOR | simonw/datasette/pulls/209 | When there's a simple (single-column) primary key, it looks weird to duplicate it in the link column. This change removes the second PK column and treats the link column as if it were the PK column from a header/sorting perspective. This might make it a bit more difficult to tell what the link for the row is, I'm not sure yet. I feel like the alternative is to change the link column to just have the text "view" or something, instead of repeating the PK. (I doubt it makes much more sense with compound PKs.) Bonus change in this PR: fix urlencoding of links in the displayed HTML. Before:  After:  | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/209/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 315327860 | MDU6SXNzdWUzMTUzMjc4NjA= | 223 | datasette publish --install=name-of-plugin | simonw 9599 | closed | 0 | 3 | 2018-04-18T04:33:59Z | 2018-04-18T14:56:17Z | 2018-04-18T14:56:17Z | OWNER | Mechanism for causing datasette publish and datasette package to install one or more additional plugins using `pip install` - refs #14 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/223/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 315548495 | MDU6SXNzdWUzMTU1NDg0OTU= | 225 | /-/(inspect|metadata|plugins)(.json)? introspection | simonw 9599 | closed | 0 | 0 | 2018-04-18T16:14:58Z | 2018-04-19T05:25:33Z | 2018-04-19T05:25:33Z | OWNER | 3 pages (and accompanying .json endpoints) for viewing: * the metadata.json that datasette was loaded with * the output of ds.inspect() * a list of installed plugins, detected by pluggy | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/225/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 315517578 | MDU6SXNzdWUzMTU1MTc1Nzg= | 224 | Ability for plugins to bundle templates | simonw 9599 | closed | 0 | 1 | 2018-04-18T14:57:53Z | 2018-04-19T05:50:36Z | 2018-04-19T05:50:36Z | OWNER | Plugins should be able to bundle templates. The Datasette template loader should then consult those plugins first when loading a template. Jinja2 has a `PackageLoader` class that can help with this: http://jinja.pocoo.org/docs/2.10/api/#jinja2.PackageLoader Refs #14 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/224/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 316365426 | MDExOlB1bGxSZXF1ZXN0MTgzMTM1NjA0 | 232 | Fix a typo | lsb 45281 | closed | 0 | 1 | 2018-04-20T18:20:04Z | 2018-04-21T00:19:08Z | 2018-04-21T00:19:08Z | CONTRIBUTOR | simonw/datasette/pulls/232 | It looks like this was the only instance of it: https://github.com/simonw/datasette/search?utf8=%E2%9C%93&q=SOLite&type= | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/232/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 316526433 | MDU6SXNzdWUzMTY1MjY0MzM= | 234 | label_column option in metadata.json | simonw 9599 | closed | 0 | 3 | 2018-04-21T21:19:08Z | 2018-04-22T20:47:12Z | 2018-04-22T20:47:12Z | OWNER | Currently the column used for displaying a foreign key relationship is automatically detected by `inspect()` by looking for tables that have a primary key column and one other column. This doesn't work for tables with more than two columns. Let's allow the table section in `metadata.json` to optionally define a `label_column` which, if present, will be used for those displays. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/234/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 316621102 | MDU6SXNzdWUzMTY2MjExMDI= | 235 | Add limit on the size in KB of data returned from a single query | simonw 9599 | open | 0 | 2 | 2018-04-22T23:01:15Z | 2018-04-24T00:30:02Z | OWNER | Datasette limits the number of rows returned to 1,000 and limits the time spent executing a SQL query to 1000ms - and both of these limits can be customized. It does not have a limit on the size of the response returned. It's possible to compose maliciously large SQL responses in a small number of rows using mechanisms like the `group_concat()` aggregate function. It would be good to avoid malicious SQL creating 100MB+ responses and potentially crashing the server. I think the easiest place to implement that is here: https://github.com/simonw/datasette/blob/f3f42957128c1e7ece584d45d9167f2ac003a3b8/datasette/app.py#L175-L190 Currently we use `cursor.fetchmany()` to fetch up to 1,001 rows at once. Instead, we could switch to iterating through `cursor.fetchone()` (or just using `for row in cursor`) and keeping a running tally of the size of the response as we go - maybe just using `rough_response_size += len(str(row))`. If that goes above a certain threshold we can terminate the response with an error, like we do with timelimits. The bigger challenge here is understanding how well this approach works and what impact it will have on overall Datasette performance. I think I need #33 for this. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/235/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 316031566 | MDU6SXNzdWUzMTYwMzE1NjY= | 228 | If spatialite detected, mark idx_XXX_Geometry tables as hidden | simonw 9599 | closed | 0 | 1 | 2018-04-19T20:37:24Z | 2018-04-26T03:25:39Z | 2018-04-26T03:25:39Z | OWNER | https://timezones-api.now.sh/timezones-faf26d0  Need to update this logic: https://github.com/simonw/datasette/blob/e2750c7cc0585adaa8c866be611089e62961ee35/datasette/app.py#L1276-L1288 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/228/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 317760361 | MDU6SXNzdWUzMTc3NjAzNjE= | 239 | Support for hidden tables in metadata.json | simonw 9599 | closed | 0 | 2 | 2018-04-25T19:21:17Z | 2018-04-26T03:45:12Z | 2018-04-26T03:43:10Z | OWNER | Since we already have a hidden feature, let's expose it more to our users | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/239/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 316128955 | MDU6SXNzdWUzMTYxMjg5NTU= | 230 | Setting page size AND max returned rows to 1000 doesn't seem to work | simonw 9599 | closed | 0 | 1 | 2018-04-20T05:05:11Z | 2018-04-26T04:04:25Z | 2018-04-26T04:04:25Z | OWNER | It appears that if the two settings are the same Datasette fails to return any results, probably because of the trick where we try to fetch 1001 rows so we know if there's a next page. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/230/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 316123256 | MDU6SXNzdWUzMTYxMjMyNTY= | 229 | Table view should support ?_size=400 parameter | simonw 9599 | closed | 0 | 1 | 2018-04-20T04:23:18Z | 2018-04-26T04:49:46Z | 2018-04-26T04:48:32Z | OWNER | Allows callers to request more rows at once. The limit will still be `max_returned_rows` (defaults to 1000). | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/229/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 269731374 | MDU6SXNzdWUyNjk3MzEzNzQ= | 44 | ?_group_count=country - return counts by specific column(s) | simonw 9599 | closed | 0 | 7 | 2017-10-30T19:50:32Z | 2018-04-26T15:09:58Z | 2018-04-26T15:09:58Z | OWNER | Imagine if this: https://stateless-datasets-jykibytogk.now.sh/flights-07d1283/airports.jsono?country__contains=gu&_group_count=country Turned into this: https://stateless-datasets-jykibytogk.now.sh/flights-07d1283?sql=select%20country,%20count(*)%20as%20group_count_country%20from%20airports%20where%20country%20like%20%27%gu%%27%20group%20by%20country%20order%20by%20group_count_country%20desc This would involve introducing a new precedent of query string arguments that start with an _ having special meanings. While we're at it, could try adding _fields=x,y,z Tasks: - [x] Get initial version working - [ ] Refactor code to not just "pretend to be a view" - [ ] Get foreign key relationships expanded | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/44/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 275135393 | MDU6SXNzdWUyNzUxMzUzOTM= | 125 | Plot rows on a map with Leaflet and Leaflet.markercluster | simonw 9599 | closed | 0 | 2 | 2017-11-19T06:05:05Z | 2018-04-26T15:14:31Z | 2018-04-26T15:14:31Z | OWNER | https://github.com/Leaflet/Leaflet.markercluster would allow us to paginate-load in an enormous set of rows with latitude/longitude points, e.g. https://australian-dunnies.now.sh/ Here's a demo of it loading 50,000 markers: https://leaflet.github.io/Leaflet.markercluster/example/marker-clustering-realworld.50000.html - and it looks like it's easy to support progress bars for if we were iteratively loading 1,000 markers at a time using datasette pagination. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/125/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 317900587 | MDU6SXNzdWUzMTc5MDA1ODc= | 240 | FTS table detection should be part of .inspect() | simonw 9599 | closed | 0 | 0 | 2018-04-26T06:58:10Z | 2018-04-29T00:04:44Z | 2018-04-29T00:04:44Z | OWNER | The code that detects if specific tables have a corresponding FTS column is currently called from TableView - it should instead be handled as part of `.inspect()`. This will make it easier to build other features that need to behave differently depending on whether a table can be searched, e.g. an autocomplete widget for selecting filters from foreign key tables. Current code: https://github.com/simonw/datasette/blob/f188ceaa2a3a5b2eab83425ad0f00cb0d364e24a/datasette/app.py#L728-L733 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/240/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 319371036 | MDExOlB1bGxSZXF1ZXN0MTg1MzA3NDA3 | 246 | ?_shape=array and _timelimit= | simonw 9599 | closed | 0 | 0 | 2018-05-02T00:18:54Z | 2018-05-02T00:20:41Z | 2018-05-02T00:20:40Z | OWNER | simonw/datasette/pulls/246 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/246/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | ||||||
| 318692953 | MDU6SXNzdWUzMTg2OTI5NTM= | 242 | Rename ?_sql_time_limit_ms= to ?_timelimit= | simonw 9599 | closed | 0 | 0 | 2018-04-29T06:11:35Z | 2018-05-02T00:20:42Z | 2018-05-02T00:20:42Z | OWNER | It's a bit of a mouthful at the moment. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/242/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 318738000 | MDU6SXNzdWUzMTg3MzgwMDA= | 244 | /-/versions page | simonw 9599 | closed | 0 | 1 | 2018-04-29T18:22:15Z | 2018-05-03T14:13:49Z | 2018-05-03T14:09:53Z | OWNER | Displays the current version of: * datasette * Python * SQLite * Spatialite (if available) Installed plugin versions should be shown on /-/plugins | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/244/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 319358200 | MDU6SXNzdWUzMTkzNTgyMDA= | 245 | ?_shape=array option | simonw 9599 | closed | 0 | 1 | 2018-05-01T23:11:07Z | 2018-05-03T14:14:33Z | 2018-05-02T00:12:20Z | OWNER | Some tools (`pandas.DataFrame(...)` for example) are happiest when you give them a raw array of JSON objects. `?_shape=array` should do just that While I'm at it, rename the default `?_shape=lists` to instead be called `?shape=arrays` And validate that `_shape` is a valid option And have `?_shape=object` return the object at the root level rather than nested in `.rows` to better match the behavior of `?_shape=array` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/245/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 320132682 | MDU6SXNzdWUzMjAxMzI2ODI= | 250 | Setup some issue templates | simonw 9599 | open | 0 | 0 | 2018-05-04T01:49:07Z | 2018-05-04T01:49:07Z | OWNER | https://twitter.com/left_pad/status/99216385740464537 I like the idea of using these to help people understand some of the ways I want to use issues. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/250/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 319954545 | MDU6SXNzdWUzMTk5NTQ1NDU= | 248 | /-/plugins should show version of each installed plugin | simonw 9599 | closed | 0 | 2 | 2018-05-03T14:50:45Z | 2018-05-04T18:25:40Z | 2018-05-04T18:05:04Z | OWNER | Refs #244 https://stackoverflow.com/questions/20180543/how-to-check-version-of-python-modules ``` >>> import pkg_resources >>> pkg_resources.get_distribution('datasette_cluster_map').version '0.4' ``` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/248/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 320090329 | MDU6SXNzdWUzMjAwOTAzMjk= | 249 | ?_size=max argument | simonw 9599 | closed | 0 | 1 | 2018-05-03T21:42:04Z | 2018-05-04T18:26:30Z | 2018-05-04T18:05:04Z | OWNER | For plugins that want to load the most data allowable, having `?_size=max` would be useful. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/249/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 317475156 | MDU6SXNzdWUzMTc0NzUxNTY= | 237 | Support for ?_search_colname=blah searches | simonw 9599 | closed | 0 | 2 | 2018-04-25T04:29:53Z | 2018-05-05T22:56:42Z | 2018-05-05T22:33:23Z | OWNER | Right now the `_search=` argument searches across all fields in a full-text index, for example: https://san-francisco.datasettes.com/sf-film-locations-84594a7/Film_Locations_in_San_Francisco?_search=justin SQLite FTS also supports searches within a specified field, for example: https://san-francisco.datasettes.com/sf-film-locations-84594a7?sql=select+rowid%2C+*+from+Film_Locations_in_San_Francisco+where+rowid+in+%28select+rowid+from+%5BFilm_Locations_in_San_Francisco_fts%5D+where+%5BLocations%5D+match+%3Asearch%29+order+by+rowid+limit+101&search=justin ``` select rowid, * from Film_Locations_in_San_Francisco where rowid in ( select rowid from [Film_Locations_in_San_Francisco_fts] where [Locations] match :search ) order by rowid limit 101 ``` The `_search=` parameter could be extended to support this using `_search_colname=`. This should also be able to support columns with spaces and special characters in their names, something like this: `_search_Column%20With%20Spaces=foo` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/237/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 321624016 | MDU6SXNzdWUzMjE2MjQwMTY= | 252 | /-/versions should report the FTS version supported by SQLite | simonw 9599 | closed | 0 | 0 | 2018-05-09T15:43:47Z | 2018-05-11T13:19:52Z | 2018-05-11T13:19:52Z | OWNER | I can copy this function from `csvs-to-sqlite`: https://github.com/simonw/csvs-to-sqlite/blob/dccbf65b37bc9eed50e9edb80a42f257e93edb1f/csvs_to_sqlite/utils.py#L283-L293 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/252/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 321631020 | MDU6SXNzdWUzMjE2MzEwMjA= | 253 | Documentation explaining how to use SQLite FTS with Datasette | simonw 9599 | closed | 0 | 1 | 2018-05-09T16:02:08Z | 2018-05-12T12:09:02Z | 2018-05-12T12:06:51Z | OWNER | In particular how to work with https://www.sqlite.org/fts3.html#_external_content_fts4_tables_ - which Datasette can automatically detect and use to add a search UI to your page. Examples of basic search setup like this: ``` CREATE VIRTUAL TABLE "interests_fts" USING FTS4 (name, content="interests"); INSERT INTO "interests_fts" (rowid, name) SELECT rowid, name FROM interests; ``` And complex join-based search setup like this: ``` CREATE VIRTUAL TABLE "interests_fts" USING FTS4 (name, category, member, content="interests"); INSERT INTO "interests_fts" (rowid, name, category, member) SELECT interests.rowid, interests.name, interest_categories.name, members.name FROM interests JOIN interest_categories ON interests.category_id = interest_categories.id JOIN members ON interests.member_id = members.id; ``` Also mention how `csvs-to-sqlite` can be used to do this easily. This will benefit from #252 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/253/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 322591993 | MDExOlB1bGxSZXF1ZXN0MTg3NjY4ODkw | 257 | Refactor views | simonw 9599 | closed | 0 | 5 | 2018-05-13T13:00:50Z | 2018-05-14T03:04:25Z | 2018-05-14T03:04:24Z | OWNER | simonw/datasette/pulls/257 | * Split out view classes from main `app.py` * Run [black](https://github.com/ambv/black) against resulting code to apply opinionated source code formatting * Run [isort](https://github.com/timothycrosley/isort) to re-order my imports Refs #256 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/257/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 322551723 | MDU6SXNzdWUzMjI1NTE3MjM= | 256 | Break up app.py into separate view modules | simonw 9599 | closed | 0 | 1 | 2018-05-12T23:56:33Z | 2018-05-14T03:05:37Z | 2018-05-14T03:05:37Z | OWNER | `views/table.py` and `views/database.py` and `views/utils.py` as a starting point. Likewise, create `tests/test_views_table.py` and `tests/test_views_database.py` - these will contain both HTML and API test for those views. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/256/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 320592643 | MDU6SXNzdWUzMjA1OTI2NDM= | 251 | Explore "distinct values for column" in inspect() | simonw 9599 | closed | 0 | 4 | 2018-05-06T13:27:24Z | 2018-05-14T22:47:55Z | 2018-05-14T22:47:55Z | OWNER | A lot of datasets have columns which have a small number of possible values in them - this one for example: https://fivethirtyeight.datasettes.com/fivethirtyeight-2628db9?sql=select+distinct+category+from+%5Binconvenient-sequel%2Fratings%5D%3B Detecting these could be interesting as part of `.inspect()`, since it would allow for various UI enhancements like autocomplete / select box filters for those columns. The problem is detecting them efficiently. `.inspect()` shouldn't spend 5 minutes churning through columns on giant tables trying to determine if they have a small collection of unique values. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/251/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 323459939 | MDExOlB1bGxSZXF1ZXN0MTg4MzEyNDEx | 261 | Facets improvements plus suggested facets | simonw 9599 | closed | 0 | 0 | 2018-05-16T03:52:39Z | 2018-05-16T15:27:26Z | 2018-05-16T15:27:25Z | OWNER | simonw/datasette/pulls/261 | Refs #255 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/261/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 323726888 | MDU6SXNzdWUzMjM3MjY4ODg= | 269 | If a facet fails due to timing out, let the user know somehow | simonw 9599 | closed | 0 | 0 | 2018-05-16T18:01:47Z | 2018-05-18T06:11:46Z | 2018-05-18T06:11:46Z | OWNER | Refs #255 - right now facets fail silently if the user requested them but they take longer than 200ms to calculate - see also #264 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/269/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 323673899 | MDU6SXNzdWUzMjM2NzM4OTk= | 264 | Make it possible to customize various facet settings | simonw 9599 | closed | 0 | 1 | 2018-05-16T15:31:34Z | 2018-05-18T06:18:00Z | 2018-05-18T05:11:52Z | OWNER | The new Facets implementation from #255 includes several hard-coded settings which should be made configurable somehow: Number of rows to return in a facet (maybe this should also be an option that can be set via quersytring argument, e.g. `?_facet=qSpecies:40`): https://github.com/simonw/datasette/blob/9959a9e4deec8e3e178f919e8b494214d5faa7fd/datasette/views/table.py#L539 Time limit for executing a facet: https://github.com/simonw/datasette/blob/9959a9e4deec8e3e178f919e8b494214d5faa7fd/datasette/views/table.py#L559-L562 Maximum unique values returned in order for a column to be suggested as a facet: https://github.com/simonw/datasette/blob/9959a9e4deec8e3e178f919e8b494214d5faa7fd/datasette/views/table.py#L646-L647 Time limit for calculating if a column should be a suggested facet: https://github.com/simonw/datasette/blob/9959a9e4deec8e3e178f919e8b494214d5faa7fd/datasette/views/table.py#L664-L667 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/264/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 323830051 | MDU6SXNzdWUzMjM4MzAwNTE= | 270 | --limit= CLI option for setting limits | simonw 9599 | closed | 0 | 1 | 2018-05-17T00:14:24Z | 2018-05-18T06:19:31Z | 2018-05-18T06:16:39Z | OWNER | #264 calls for four new datasette limit options, on top of the two existing ones: * `--max_returned_rows` * `--sql_time_limit_ms` These are already clogging up `datasette serve --help` a bit. How about this syntax instead? datasette --limit max_returned_rows:100 \ --limit facet_timeout_ms:500 demo.db Then we can add as many new user over-rideable limits as we like without clogging up `--help` too much - though it would be good to have a way of optionally listings their documentation as well. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/270/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 324652142 | MDU6SXNzdWUzMjQ2NTIxNDI= | 274 | Rename --limit to --config, add --help-config | simonw 9599 | closed | 0 | 2 | 2018-05-19T18:57:42Z | 2018-05-20T17:04:55Z | 2018-05-20T17:04:11Z | OWNER | #270 introduced `--limit` but on further thought it should be called `--config` instead. `--page_size` should becomes `--config default_page_size:1000` Add `--help-config` to show full help showing all config settings. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/274/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 322741659 | MDExOlB1bGxSZXF1ZXN0MTg3NzcwMzQ1 | 258 | Add new metadata key persistent_urls which removes the hash from all database urls | philroche 247131 | closed | 0 | 3 | 2018-05-14T09:39:18Z | 2018-05-21T07:38:15Z | 2018-05-21T07:38:15Z | NONE | simonw/datasette/pulls/258 | Add new metadata key "persistent_urls" which removes the hash from all database urls when set to "true" This PR is just to gauge if this, or something like it, is something you would consider merging? I understand the reason why the substring of the hash is included in the url but there are some use cases where the urls should persist across deployments. For bookmarks for example or for scripts that use the JSON API. This is the initial commit for this feature. Tests and documentation updates to follow. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/258/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 319449852 | MDU6SXNzdWUzMTk0NDk4NTI= | 247 | SQLite code decoupled from Datasette | jsancho-gpl 11912854 | open | 0 | 1 | 2018-05-02T08:03:28Z | 2018-05-21T15:29:31Z | NONE | I'm working on the possibility of use Datasette with other file formats that aren't SQLite, like files with [PyTables](https://github.com/PyTables/PyTables) format. In order to accomplish that, I've started [a fork for decoupling the code related with SQLite](https://github.com/jsancho-gpl/datasette/tree/feature/db-type-plugin) and putting it in an external connector to allow future connectors for a lot of file formats. It'd be nice if you could look at it and suggest improvements for a possible PR. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/247/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 324836533 | MDExOlB1bGxSZXF1ZXN0MTg5MzE4NDUz | 277 | Refactor inspect logic | russss 45057 | closed | 0 | 2 | 2018-05-21T08:49:31Z | 2018-05-22T16:07:24Z | 2018-05-22T14:03:07Z | CONTRIBUTOR | simonw/datasette/pulls/277 | This pulls the logic for inspect out into a new file which makes it a bit easier to understand. This was going to be the first part of an implementation for #276, but it seems like that might take a while so I'm going to PR a few bits of refactoring individually. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/277/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 324451322 | MDU6SXNzdWUzMjQ0NTEzMjI= | 273 | Figure out a way to have /-/version return current git commit hash | simonw 9599 | closed | 0 | 2 | 2018-05-18T15:16:56Z | 2018-05-22T19:35:22Z | 2018-05-22T19:35:22Z | OWNER | https://fivethirtyeight.datasettes.com/-/versions reports Datasette version `0.21` This isn't actually correct. The deploy script for that site actually deploys current master using `https://github.com/simonw/datasette/archive/master.zip`: https://github.com/simonw/fivethirtyeight-datasette/blob/66b4b0dfedd7237bc8c02d3e26d905bca7b84069/Dockerfile#L9 Ideally this would show the current commit hash, but I'm not at all sure if it's possible to derive that from `pip install https://github.com/simonw/datasette/archive/master.zip`. Is there another mechanism that could be used to reliably `pip install` current master but still provide access to the most recent commit hash? | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/273/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 325352370 | MDExOlB1bGxSZXF1ZXN0MTg5NzA3Mzc0 | 279 | Add version number support with Versioneer | rgieseke 198537 | closed | 0 | 4 | 2018-05-22T15:39:45Z | 2018-05-22T19:35:23Z | 2018-05-22T19:35:22Z | CONTRIBUTOR | simonw/datasette/pulls/279 | I think that's all for getting Versioneer support, I've been happily using it in a couple of projects ... ``` In [2]: datasette.__version__ Out[2]: '0.22+3.g6e12445' ``` Repo: https://github.com/warner/python-versioneer Versioneer Licence: Public Domain (CC0-1.0) Closes #273 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/279/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 325705981 | MDU6SXNzdWUzMjU3MDU5ODE= | 282 | Faceting breaks pagination | simonw 9599 | closed | 0 | 1 | 2018-05-23T13:29:47Z | 2018-05-23T13:53:39Z | 2018-05-23T13:42:07Z | OWNER | e.g. on https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3/nba-elo%2Fnbaallelo?_facet=lg_id#facet-lg_id - click the "next page" link: https://fivethirtyeight.datasettes.com/fivethirtyeight-5de27e3/nba-elo%2Fnbaallelo?_facet=lg_id&_next=100 Invalid SQL: near "and": syntax error | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/282/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 325294102 | MDU6SXNzdWUzMjUyOTQxMDI= | 278 | Build smallest possible Docker image with Datasette plus recent SQLite (with json1) plus Spatialite 4.4.0 | simonw 9599 | closed | 0 | 3 | 2018-05-22T13:28:40Z | 2018-05-23T17:43:36Z | 2018-05-23T17:43:36Z | OWNER | A Dockerfile that does the following: * Bundles Datasette master * Python 3.6 most recent version (or 3.7 if it has been released) * SQLite 3.23.1 (or most recent release) such that "import sqite3" in Python gets that version. Ideally with the json1 module baked in by default, but having it loadable as an optional module is fine too * SpatiaLite 4.4.0-RC0 (or most recent version) such that it can be loaded as an optional module * Uses multi-stage builds to stay as small as possible Note that the current "release" of SpatiaLite is 4.3.0 which is missing key features like https://www.gaia-gis.it/fossil/libspatialite/wiki?name=KNN - 4.4.0 probably needs to be compiled from source. I don't know the best way to get a current SQLite version bundled for Python 3. Maybe https://github.com/coleifer/pysqlite3 ? | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/278/reactions", "total_count": 2, "+1": 2, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 326182814 | MDU6SXNzdWUzMjYxODI4MTQ= | 284 | Ability to enable/disable specific features via --config | simonw 9599 | closed | 0 | 5 | 2018-05-24T15:47:56Z | 2018-05-25T06:05:02Z | 2018-05-25T05:51:09Z | OWNER | `--config` settings from #274 can currently only be integers. I'd like them to be available as boooeans too. Then we can use them to have that are turned on by default but can be turned off. First features to get this treatment: - [x] `allow_sql` - whether or not the `?sql=` parameter is allowed and form is displayed - [X] `allow_facet` - is `?_facet=` allowed or do we only run facets defined in `metadata.json` - [X] `allow_download` - do we let users download the full SQLite database file? - [X] `suggest_facets` - do we attempt to calculate suggested facets? Refs #275 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/284/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 326599525 | MDU6SXNzdWUzMjY1OTk1MjU= | 286 | Database hash should include current datasette version | simonw 9599 | open | 0 | 2 | 2018-05-25T17:03:42Z | 2018-05-25T17:07:36Z | OWNER | Right now deploying a new version of datasette doesn't invalidate existing URLs, so users may still see a cached copy of the old templates. We can fix this by including the current datasette version in the input to the hash function (which currently just the database file contents). | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/286/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 325553991 | MDExOlB1bGxSZXF1ZXN0MTg5ODYwMDUy | 281 | Reduces image size using Alpine + Multistage (re: #278) | iMerica 487897 | closed | 0 | 1 | 2018-05-23T05:27:05Z | 2018-05-26T02:10:38Z | 2018-05-26T02:10:38Z | NONE | simonw/datasette/pulls/281 | Hey Simon! I got the image size down from 256MB to 110MB. Seems to be working okay, but you might want to test it a bit more. Example output of `docker run --rm -it <my-tag> datasette` ``` Serve! files=() on port 8001 [2018-05-23 05:23:08 +0000] [1] [INFO] Goin' Fast @ http://127.0.0.1:8001 [2018-05-23 05:23:08 +0000] [1] [INFO] Starting worker [1] ``` Related: https://github.com/simonw/datasette/issues/278 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/281/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 326768188 | MDU6SXNzdWUzMjY3NjgxODg= | 289 | ?_ttl= parameter to control caching | simonw 9599 | closed | 0 | 3 | 2018-05-26T21:22:55Z | 2018-05-26T22:22:47Z | 2018-05-26T22:17:48Z | OWNER | This would allow clients to specify the max-age caching header that should be returned with the query. Most important this will allow caching to be completely urned off for specific queries using `?_ttl=0`. Sending 0 should cause a `Cache-Control: no-cache` header to be returned. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/289/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 326617744 | MDU6SXNzdWUzMjY2MTc3NDQ= | 287 | ?_shape=arrayfirst | simonw 9599 | closed | 0 | 1 | 2018-05-25T18:11:03Z | 2018-05-27T00:32:53Z | 2018-05-27T00:32:29Z | OWNER | Return an array of single items (the first item in each row returned from the SQL query). | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/287/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 326778161 | MDU6SXNzdWUzMjY3NzgxNjE= | 290 | Consider increasing the default for num_sql_threads (currently 3) | simonw 9599 | open | 0 | 0 | 2018-05-27T00:52:41Z | 2018-05-27T00:52:41Z | OWNER | I ran a very rough micro-benchmark on the new `num_sql_threads` config option (added in #285) datasette --config num_sql_threads:1 fivethirtyeight.db Then ab -n 100 -c 10 'http://127.0.0.1:8011/fivethirtyeight-2628db9/twitter-ratio%2Fsenators' | Number of threads | Requests/second | |---|---| | 1 | 4.57 | | 3 | 9.77 | | 10 | 13.53 | | 20 | 15.24 | 50 | 8.21 | This was on my early 2018 OS X laptop. Need to benchmark in other common environments before making a decision on changing the default. That said, the default of 3 was a number I plucked out of thin air. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/290/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 326189744 | MDU6SXNzdWUzMjYxODk3NDQ= | 285 | num_threads and cache_max_age should be --config options | simonw 9599 | closed | 0 | 2 | 2018-05-24T16:04:51Z | 2018-05-27T00:53:35Z | 2018-05-27T00:43:33Z | OWNER | https://github.com/simonw/datasette/blob/58b5a37dbbf13868a46bcbb284509434e66eca25/datasette/app.py#L106 And https://github.com/simonw/datasette/blob/58b5a37dbbf13868a46bcbb284509434e66eca25/datasette/views/base.py#L325 Refs #275 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/285/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 276704327 | MDU6SXNzdWUyNzY3MDQzMjc= | 150 | _group_count= feature improvements | simonw 9599 | closed | 0 | 3 | 2017-11-24T22:06:18Z | 2018-05-28T16:41:28Z | 2018-05-28T16:41:28Z | OWNER | - [ ] The "apply filters" form should keep you on the _group_count= page - [ ] Foreign key references should be expand - [ ] Page title should reflect the view you are on | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/150/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 274884209 | MDU6SXNzdWUyNzQ4ODQyMDk= | 116 | Add documentation section about SQLite extensions | simonw 9599 | closed | 0 | 1 | 2017-11-17T14:36:30Z | 2018-05-28T17:23:42Z | 2018-05-28T17:23:41Z | OWNER | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/116/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||||
| 273569068 | MDU6SXNzdWUyNzM1NjkwNjg= | 79 | Add more detailed API documentation to the README | simonw 9599 | closed | 0 | 3 | 2017-11-13T20:36:21Z | 2018-05-28T17:24:48Z | 2018-05-28T17:24:48Z | OWNER | Need to document: - [ ] The ?column__gt=4 style filter arguments for tables - [ ] The ?sql= API, and how named parameters work - [ ] How API pagination works - [ ] How redirects and cache headers work | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/79/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed |
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[pull_request] TEXT,
[body] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
, [active_lock_reason] TEXT, [performed_via_github_app] TEXT, [reactions] TEXT, [draft] INTEGER, [state_reason] TEXT);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);