issues
74 rows where comments = 7
This data as json, CSV (advanced)
Suggested facets: user, milestone, repo, state_reason, created_at (date)
| id ▼ | node_id | number | title | user | state | locked | assignee | milestone | comments | created_at | updated_at | closed_at | author_association | pull_request | body | repo | type | active_lock_reason | performed_via_github_app | reactions | draft | state_reason |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 269731374 | MDU6SXNzdWUyNjk3MzEzNzQ= | 44 | ?_group_count=country - return counts by specific column(s) | simonw 9599 | closed | 0 | 7 | 2017-10-30T19:50:32Z | 2018-04-26T15:09:58Z | 2018-04-26T15:09:58Z | OWNER | Imagine if this: https://stateless-datasets-jykibytogk.now.sh/flights-07d1283/airports.jsono?country__contains=gu&_group_count=country Turned into this: https://stateless-datasets-jykibytogk.now.sh/flights-07d1283?sql=select%20country,%20count(*)%20as%20group_count_country%20from%20airports%20where%20country%20like%20%27%gu%%27%20group%20by%20country%20order%20by%20group_count_country%20desc This would involve introducing a new precedent of query string arguments that start with an _ having special meanings. While we're at it, could try adding _fields=x,y,z Tasks: - [x] Get initial version working - [ ] Refactor code to not just "pretend to be a view" - [ ] Get foreign key relationships expanded | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/44/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 273127694 | MDU6SXNzdWUyNzMxMjc2OTQ= | 57 | Ship a Docker image of the whole thing | simonw 9599 | closed | 0 | 7 | 2017-11-11T07:51:28Z | 2018-06-28T04:01:51Z | 2018-06-28T04:01:38Z | OWNER | The generated Docker images can then just inherit from that. This will speed up deploys as no need to `pip install` anything. - [x] Ship that image to Docker Hub - [ ] Update the generated Dockerfile to use it | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/57/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 289425975 | MDExOlB1bGxSZXF1ZXN0MTYzNTYxODMw | 181 | add "format sql" button to query page, uses sql-formatter | bsmithgall 1957344 | closed | 0 | 7 | 2018-01-17T21:50:04Z | 2019-11-11T03:08:25Z | 2019-11-11T03:08:25Z | NONE | simonw/datasette/pulls/181 | Cool project! This fixes #136 using the suggested [sql formatter](https://github.com/zeroturnaround/sql-formatter) library. I included the minified version in the bundle and added the relevant scripts to the codemirror includes instead of adding new files, though I could also add new files. I wanted to keep it all together, since the result of the format needs access to the editor in order to properly update the codemirror instance. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/181/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 309033998 | MDU6SXNzdWUzMDkwMzM5OTg= | 187 | Windows installation error | robmarkcole 11855322 | closed | 0 | 7 | 2018-03-27T16:04:37Z | 2019-06-15T21:44:23Z | 2019-06-15T21:44:23Z | NONE | On attempting install on a Win 7 PC with py 3.6.2 (Anaconda dist) I get the error: ``` Collecting uvloop>=0.5.3 (from Sanic==0.7.0->datasette) Downloading uvloop-0.9.1.tar.gz (1.8MB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.8MB 12.8MB/s Complete output from command python setup.py egg_info: Traceback (most recent call last): File "<string>", line 1, in <module> File "C:\Users\RCole\AppData\Local\Temp\pip-build-juakfqt8\uvloop\setup.py ", line 10, in <module> raise RuntimeError('uvloop does not support Windows at the moment') RuntimeError: uvloop does not support Windows at the moment ``` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/187/reactions", "total_count": 4, "+1": 4, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 309558826 | MDU6SXNzdWUzMDk1NTg4MjY= | 190 | Keyset pagination doesn't work correctly for compound primary keys | simonw 9599 | closed | 0 | 7 | 2018-03-28T22:45:06Z | 2018-03-30T06:31:15Z | 2018-03-30T06:26:28Z | OWNER | Consider https://datasette-issue-190-compound-pks.now.sh/compound-pks-9aafe8f/compound_primary_key  The next= link is to `d,v`: https://datasette-issue-190-compound-pks.now.sh/compound-pks-9aafe8f/compound_primary_key?_next=d%2Cv But that page starts with: 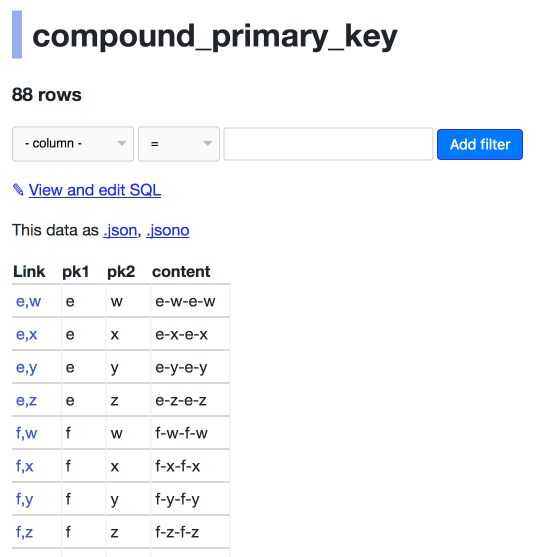 The next key in the sequence should be `d,w`. Also we should return the full a-z of the ones that start with the letter e - in this example we only return `e-w`, `e-x`, `e-y` and `e-z` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/190/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 323223872 | MDU6SXNzdWUzMjMyMjM4NzI= | 260 | Validate metadata.json on startup | simonw 9599 | open | 0 | 7 | 2018-05-15T13:42:56Z | 2023-06-21T12:51:22Z | OWNER | It's easy to misspell the name of a database or table and then be puzzled when the metadata settings silently fail. To avoid this, let's sanity check the provided metadata.json on startup and quit with a useful error message if we find any obvious mistakes. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/260/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 327365110 | MDU6SXNzdWUzMjczNjUxMTA= | 294 | inspect should record column types | simonw 9599 | open | 0 | 7 | 2018-05-29T15:10:41Z | 2019-06-28T16:45:28Z | OWNER | For each table we want to know the columns, their order and what type they are. I'm going to break with SQLite defaults a little on this one and allow datasette to define additional types - to start with just a `geometry` type for columns that are detected as SpatiaLite geometries. Possible JSON design: "columns": [{ "name": "title", "type": "text" }, ...] Refs #276 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/294/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 336465018 | MDU6SXNzdWUzMzY0NjUwMTg= | 329 | Travis should push tagged images to Docker Hub for each release | simonw 9599 | closed | 0 | 7 | 2018-06-28T04:01:31Z | 2018-11-05T06:54:10Z | 2018-11-05T06:53:28Z | OWNER | https://sebest.github.io/post/using-travis-ci-to-build-docker-images/ | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/329/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 413868452 | MDU6SXNzdWU0MTM4Njg0NTI= | 17 | Improve and document foreign_keys=... argument to insert/create/etc | simonw 9599 | closed | 0 | 7 | 2019-02-24T21:09:11Z | 2019-02-24T23:45:48Z | 2019-02-24T23:45:48Z | OWNER | The `foreign_keys=` argument to `table.insert_all()` and friends can be used to specify foreign key relationships that should be created. It is not yet documented. It also requires you to specify the SQLite type of each column, even though this can be detected by introspecting the referenced table: cols = [c for c in self.db[other_table].columns if c.name == other_column] cols[0].type Relates to #2 | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/17/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 432636432 | MDU6SXNzdWU0MzI2MzY0MzI= | 429 | ?_where=sql-fragment parameter for table views | simonw 9599 | closed | 0 | 7 | 2019-04-12T15:58:51Z | 2019-04-15T10:48:01Z | 2019-04-13T01:37:25Z | OWNER | Only available if arbitrary SQL is enabled (the default). `?_where=id in (1,2,3)&_where=id in (select tag_id from tags)` Allows any table (or view) page to have arbitrary additional `extra_where` clauses defined using the URL! This would be extremely useful for building JavaScript applications against the Datasette API that only need on extra tiny bit of SQL but still want to benefit from other table view features like faceting. Would be nice if this could take `:named` parameters and have them filled in via querystring as well. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/429/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 440134714 | MDU6SXNzdWU0NDAxMzQ3MTQ= | 446 | Define mechanism for plugins to return structured data | simonw 9599 | closed | 0 | Datasette 1.0 3268330 | 7 | 2019-05-03T17:00:16Z | 2020-10-02T00:08:54Z | 2020-10-02T00:08:47Z | OWNER | Several plugin hooks now expect plugins to return data in a specific shape - notably the new output format hook and the custom facet hook. These use Python dictionaries right now but that's quite error prone: it would be good to have a mechanism that supported a more structured format. Full list of current hooks is here: https://datasette.readthedocs.io/en/latest/plugins.html#plugin-hooks | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/446/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 497171390 | MDU6SXNzdWU0OTcxNzEzOTA= | 577 | Utility mechanism for plugins to render templates | simonw 9599 | closed | 0 | Datasette 1.0 3268330 | 7 | 2019-09-23T15:30:36Z | 2020-02-04T20:26:20Z | 2020-02-04T20:26:19Z | OWNER | Sometimes a plugin will need to render a template for some custom UI. We need a documented API for doing this, which ensures that everything will work correctly if you extend base.html etc. See also #576. This could be a `.render()` method on the Datasette class, but that feels a bit weird - should that class also take responsibility for rendering? | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/577/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 520681725 | MDU6SXNzdWU1MjA2ODE3MjU= | 621 | Syntax for ?_through= that works as a form field | simonw 9599 | open | 0 | 7 | 2019-11-11T00:19:03Z | 2021-12-18T01:42:33Z | OWNER | The current syntax for `?_through=` uses JSON to avoid any risk of confusion with table or column names that contain special characters. This means you can't target a form field at it. We should be able to support both - `?x.y.z=value` for tables and columns with "regular" names, falling back to the current JSON syntax for columns or tables that won't work with the key/value syntax. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/621/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 564579430 | MDU6SXNzdWU1NjQ1Nzk0MzA= | 86 | Problem with square bracket in CSV column name | foscoj 8149512 | closed | 0 | 7 | 2020-02-13T10:19:57Z | 2020-02-27T04:16:08Z | 2020-02-27T04:16:07Z | NONE | testing some data from european power information (entsoe.eu), the title of the csv contains square brackets. as I am playing with glitch, sqlite-utils are used for creating the db. Traceback (most recent call last): File "/app/.local/bin/sqlite-utils", line 8, in <module> sys.exit(cli()) File "/app/.local/lib/python3.7/site-packages/click/core.py", line 764, in __call__ return self.main(*args, **kwargs) File "/app/.local/lib/python3.7/site-packages/click/core.py", line 717, in main rv = self.invoke(ctx) File "/app/.local/lib/python3.7/site-packages/click/core.py", line 1137, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/app/.local/lib/python3.7/site-packages/click/core.py", line 956, in invoke return ctx.invoke(self.callback, **ctx.params) File "/app/.local/lib/python3.7/site-packages/click/core.py", line 555, in invoke return callback(*args, **kwargs) File "/app/.local/lib/python3.7/site-packages/sqlite_utils/cli.py", line 434, in insert default=default, File "/app/.local/lib/python3.7/site-packages/sqlite_utils/cli.py", line 384, in insert_upsert_implementation docs, pk=pk, batch_size=batch_size, alter=alter, **extra_kwargs File "/app/.local/lib/python3.7/site-packages/sqlite_utils/db.py", line 997, in insert_all extracts=extracts, File "/app/.local/lib/python3.7/site-packages/sqlite_utils/db.py", line 618, in create extracts=extracts, File "/app/.local/lib/python3.7/site-packages/sqlite_utils/db.py", line 310, in create_table self.conn.execute(sql) sqlite3.OperationalError: unrecognized token: "]" entsoe_2016.csv renamed to txt for uploading compatibility [entsoe_2016.txt](https://github.com/simonw/sqlite-utils/files/4197688/entsoe_2016.txt) code is remixed directly from your https://glitch.com/edit/#!/datasette-csvs repo | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/86/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 576711589 | MDU6SXNzdWU1NzY3MTE1ODk= | 695 | Update SQLite bundled with Docker container | simonw 9599 | closed | 0 | 7 | 2020-03-06T05:42:12Z | 2020-03-08T23:33:23Z | 2020-03-06T06:15:27Z | OWNER | It's 3.26.0 at the moment: https://github.com/simonw/datasette/blob/af9cd4ca64652fae262e6f7b5d201f6e0adc989b/Dockerfile#L9-L11 Most recent release is 3.31.1: https://www.sqlite.org/releaselog/3_31_1.html | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/695/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 577578306 | MDU6SXNzdWU1Nzc1NzgzMDY= | 697 | index.html is not reliably loaded from a plugin | simonw 9599 | closed | 0 | 7 | 2020-03-08T22:37:55Z | 2020-03-08T23:33:28Z | 2020-03-08T23:11:27Z | OWNER | Lots of detail in https://github.com/simonw/datasette-search-all/issues/2 - short version is that I have a plugin with its own `index.html` template and Datasette intermittently fails to load it and uses the default `index.html` that ships with Datasette instead. Related: * #689: "Templates considered" comment broken in >=0.35 * #693: Variables from extra_template_vars() not exposed in _context=1 (may as well fix this while I'm in there) | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/697/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 581339961 | MDU6SXNzdWU1ODEzMzk5NjE= | 92 | .columns_dict doesn't work for all possible column types | simonw 9599 | closed | 0 | 7 | 2020-03-14T19:30:35Z | 2020-03-15T18:37:43Z | 2020-03-14T20:04:14Z | OWNER | Got this error: ``` File ".../python3.7/site-packages/sqlite_utils/db.py", line 462, in <dictcomp> for column in self.columns KeyError: 'REAL' ``` `.columns_dict` uses `REVERSE_COLUMN_TYPE_MAPPING`: https://github.com/simonw/sqlite-utils/blob/43f1c6ab4e3a6b76531fb6f5447adb83d26f3971/sqlite_utils/db.py#L457-L463 `REVERSE_COLUMN_TYPE_MAPPING` defines `FLOAT` not `REAL`A https://github.com/simonw/sqlite-utils/blob/43f1c6ab4e3a6b76531fb6f5447adb83d26f3971/sqlite_utils/db.py#L68-L74 | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/92/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 597671518 | MDU6SXNzdWU1OTc2NzE1MTg= | 98 | Only set .last_rowid and .last_pk for single update/inserts, not for .insert_all()/.upsert_all() with multiple records | simonw 9599 | closed | 0 | 7 | 2020-04-10T03:19:40Z | 2021-09-28T04:38:44Z | 2020-04-13T03:29:15Z | OWNER | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/98/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||||
| 612151767 | MDU6SXNzdWU2MTIxNTE3Njc= | 15 | Expose scores from ZCOMPUTEDASSETATTRIBUTES | simonw 9599 | closed | 0 | 7 | 2020-05-04T20:36:07Z | 2020-12-20T04:44:22Z | 2020-05-05T00:11:45Z | MEMBER | The Apple Photos database has a `ZCOMPUTEDASSETATTRIBUTES` that looks absurdly interesting... it has calculated scores for every photo: <img width="273" alt="Photos__ZCOMPUTEDASSETATTRIBUTES" src="https://user-images.githubusercontent.com/9599/81011044-1f0e3d00-8e0c-11ea-84b6-f302b09e7bc9.png"> | dogsheep-photos 256834907 | issue | {"url": "https://api.github.com/repos/dogsheep/dogsheep-photos/issues/15/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 642388564 | MDU6SXNzdWU2NDIzODg1NjQ= | 858 | publish heroku does not work on Windows 10 | simonlau 870912 | open | 0 | 7 | 2020-06-20T14:40:28Z | 2021-06-10T17:44:09Z | NONE | When executing "datasette publish heroku schools.db" on Windows 10, I get the following error ```shell File "c:\users\dell\.virtualenvs\sec-schools-jn-cwk8z\lib\site-packages\datasette\publish\heroku.py", line 54, in heroku line.split()[0] for line in check_output(["heroku", "plugins"]).splitlines() File "c:\python38\lib\subprocess.py", line 411, in check_output return run(*popenargs, stdout=PIPE, timeout=timeout, check=True, File "c:\python38\lib\subprocess.py", line 489, in run with Popen(*popenargs, **kwargs) as process: File "c:\python38\lib\subprocess.py", line 854, in __init__ self._execute_child(args, executable, preexec_fn, close_fds, File "c:\python38\lib\subprocess.py", line 1307, in _execute_child hp, ht, pid, tid = _winapi.CreateProcess(executable, args, FileNotFoundError: [WinError 2] The system cannot find the file specified ``` Changing https://github.com/simonw/datasette/blob/55a6ffb93c57680e71a070416baae1129a0243b8/datasette/publish/heroku.py#L54 to ```python line.split()[0] for line in check_output(["heroku", "plugins"], shell=True).splitlines() ``` as well as the other `check_output()` and `call()` within the same file leads me to another recursive error about temp files | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/858/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 651159727 | MDU6SXNzdWU2NTExNTk3Mjc= | 41 | Demo is failing to deploy | simonw 9599 | closed | 0 | 7 | 2020-07-05T22:40:33Z | 2020-07-06T01:07:03Z | 2020-07-06T01:07:02Z | MEMBER | https://github.com/dogsheep/github-to-sqlite/runs/837714622?check_suite_focus=true ``` Creating Revision.........................................................................................................................................failed Deployment failed ERROR: (gcloud.run.deploy) Cloud Run error: Container failed to start. Failed to start and then listen on the port defined by the PORT environment variable. Logs for this revision might contain more information. Traceback (most recent call last): File "/opt/hostedtoolcache/Python/3.8.3/x64/bin/datasette", line 8, in <module> sys.exit(cli()) File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/site-packages/click/core.py", line 829, in __call__ return self.main(*args, **kwargs) File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/site-packages/click/core.py", line 782, in main rv = self.invoke(ctx) File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/site-packages/click/core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/site-packages/click/core.py", line 1259, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/site-packages/click/core.py", line 1066, in invoke return ctx.invoke(self.callback, **ctx.params) File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/site-packages/click/core.py", line 610, in invoke return callback(*args, **kwargs) File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/site-packages/datasette/publish/cloudrun.py", line 138, in cloudrun check_call( File "/opt/hostedtoolcache/Python/3.8.3/x64/lib/python3.8/subprocess.py", line 364, in check_call raise CalledProcessError(retcode, cmd) subprocess.CalledProcessError: Command 'gcloud run deploy --allow-unauthenticated --platform=managed --image gcr.io/datasette-222320/datasette github-to-sqlite' returned non-zero exit sta… | github-to-sqlite 207052882 | issue | {"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/41/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 672421411 | MDU6SXNzdWU2NzI0MjE0MTE= | 916 | Support reverse pagination (previous page, has-previous-items) | simonw 9599 | open | 0 | 7 | 2020-08-04T00:32:06Z | 2021-04-03T23:43:11Z | OWNER | I need this for `datasette-graphql` for full compatibility with the way Relay likes to paginate - using cursors for paginating backwards as well as for paginating forwards. > This may be the kick I need to get Datasette pagination to work in reverse too. _Originally posted by @simonw in https://github.com/simonw/datasette-graphql/issues/2#issuecomment-668305853_ | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/916/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 677926613 | MDU6SXNzdWU2Nzc5MjY2MTM= | 931 | Docker container is no longer being pushed (it's stuck on 0.45) | simonw 9599 | closed | 0 | 7 | 2020-08-12T19:33:03Z | 2020-08-12T21:36:20Z | 2020-08-12T21:36:20Z | OWNER | e.g. https://travis-ci.org/github/simonw/datasette/jobs/717123725 Here's how it broke: ``` --2020-08-12 03:08:17-- https://www.gaia-gis.it/gaia-sins/freexl-1.0.5.tar.gz Resolving www.gaia-gis.it (www.gaia-gis.it)... 212.83.162.51 Connecting to www.gaia-gis.it (www.gaia-gis.it)|212.83.162.51|:443... connected. HTTP request sent, awaiting response... 404 Not Found 2020-08-12 03:08:18 ERROR 404: Not Found. The command '/bin/sh -c wget "https://www.gaia-gis.it/gaia-sins/freexl-1.0.5.tar.gz" && tar zxf freexl-1.0.5.tar.gz && cd freexl-1.0.5 && ./configure && make && make install' returned a non-zero code: 8 The command "docker build -f Dockerfile -t $REPO:$TRAVIS_TAG ." exited with 8. 0.07s$ docker tag $REPO:$TRAVIS_TAG $REPO:latest Error response from daemon: No such image: [secure]/datasette:0.47.1 The command "docker tag $REPO:$TRAVIS_TAG $REPO:latest" exited with 1. 0.08s$ docker push $REPO The push refers to repository [docker.io/[secure]/datasette] An image does not exist locally with the tag: [secure]/datasette The command "docker push $REPO" exited with 1. cache.2 store build cache ``` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/931/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 686978131 | MDU6SXNzdWU2ODY5NzgxMzE= | 139 | insert_all(..., alter=True) should work for new columns introduced after the first 100 records | simonwiles 96218 | closed | 0 | 7 | 2020-08-27T06:25:25Z | 2020-08-28T22:48:51Z | 2020-08-28T22:30:14Z | CONTRIBUTOR | Is there a way to make `.insert_all()` work properly when new columns are introduced outside the first 100 records (with or without the `alter=True` argument)? I'm using `.insert_all()` to bulk insert ~3-4k records at a time and it is common for records to need to introduce new columns. However, if new columns are introduced after the first 100 records, `sqlite_utils` doesn't even raise the `OperationalError: table ... has no column named ...` exception; it just silently drops the extra data and moves on. It took me a while to find this little snippet in the [documentation for `.insert_all()`](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts) (it's not mentioned under [Adding columns automatically on insert/update](https://sqlite-utils.readthedocs.io/en/stable/python-api.html#bulk-inserts)): > The column types used in the CREATE TABLE statement are automatically derived from the types of data in that first batch of rows. **_Any additional or missing columns in subsequent batches will be ignored._** I tried changing the `batch_size` argument to the total number of records, but it seems only to effect the number of rows that are committed at a time, and has no influence on this problem. Is there a way around this that you would suggest? It seems like it should raise an exception at least. | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/139/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 688427751 | MDU6SXNzdWU2ODg0Mjc3NTE= | 956 | Push to Docker Hub failed - but it shouldn't run for alpha releases anyway | simonw 9599 | closed | 0 | 7 | 2020-08-29T01:09:12Z | 2020-09-15T20:46:41Z | 2020-09-15T20:36:34Z | OWNER | https://github.com/simonw/datasette/runs/1043709494?check_suite_focus=true <img width="740" alt="Release_notes_for_0_49a0_·_simonw_datasette_7178126" src="https://user-images.githubusercontent.com/9599/91625110-80c55a80-e959-11ea-8fea-70508c53fcfb.png"> - [x] This step should not run if a release is an alpha or beta - [x] When it DOES run it should work - [x] See it work for both an alpha and a non-alpha release, then close this ticket | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/956/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 688622148 | MDU6SXNzdWU2ODg2MjIxNDg= | 957 | Simplify imports of common classes | simonw 9599 | closed | 0 | Datasette 1.0 3268330 | 7 | 2020-08-29T23:44:04Z | 2022-02-06T06:36:41Z | 2022-02-06T06:34:37Z | OWNER | There are only a few classes that plugins need to import. It would be nice if these imports were as short and memorable as possible. For example: ```python from datasette.app import Datasette from datasette.utils.asgi import Response ``` Could both become: ```python from datasette import Datasette from datasette import Response ``` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/957/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 688670158 | MDU6SXNzdWU2ODg2NzAxNTg= | 147 | SQLITE_MAX_VARS maybe hard-coded too low | simonwiles 96218 | open | 0 | 7 | 2020-08-30T07:26:45Z | 2021-02-15T21:27:55Z | CONTRIBUTOR | I came across this while about to open an issue and PR against the documentation for `batch_size`, which is a bit incomplete. As mentioned in #145, while: > [`SQLITE_MAX_VARIABLE_NUMBER`](https://www.sqlite.org/limits.html#max_variable_number) ... defaults to 999 for SQLite versions prior to 3.32.0 (2020-05-22) or 32766 for SQLite versions after 3.32.0. it is common that it is increased at compile time. Debian-based systems, for example, seem to ship with a version of sqlite compiled with SQLITE_MAX_VARIABLE_NUMBER set to 250,000, and I believe this is the case for homebrew installations too. In working to understand what `batch_size` was actually doing and why, I realized that by setting `SQLITE_MAX_VARS` in `db.py` to match the value my sqlite was compiled with (I'm on Debian), I was able to decrease the time to `insert_all()` my test data set (~128k records across 7 tables) from ~26.5s to ~3.5s. Given that this about .05% of my total dataset, this is time I am keen to save... Unfortunately, it seems that `sqlite3` in the python standard library doesn't expose the `get_limit()` C API (even though `pysqlite` used to), so it's hard to know what value sqlite has been compiled with (note that this could mean, I suppose, that it's less than 999, and even hardcoding `SQLITE_MAX_VARS` to the conservative default might not be adequate. It can also be lowered -- but not raised -- at runtime). The best I could come up with is `echo "" | sqlite3 -cmd ".limits variable_number"` (only available in `sqlite >= 2015-05-07 (3.8.10)`). Obviously this couldn't be relied upon in `sqlite_utils`, but I wonder what your opinion would be about exposing `SQLITE_MAX_VARS` as a user-configurable parameter (with suitable "here be dragons" warnings)? I'm going to go ahead and monkey-patch it for my purposes in any event, but it seems like it might be worth considering. | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/147/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 703218756 | MDU6SXNzdWU3MDMyMTg3NTY= | 50 | Commands for making authenticated API calls | simonw 9599 | open | 0 | 7 | 2020-09-17T02:39:07Z | 2020-10-19T05:01:29Z | MEMBER | Similar to `twitter-to-sqlite fetch`, see https://github.com/dogsheep/twitter-to-sqlite/issues/51 | github-to-sqlite 207052882 | issue | {"url": "https://api.github.com/repos/dogsheep/github-to-sqlite/issues/50/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 705215230 | MDU6SXNzdWU3MDUyMTUyMzA= | 26 | Pagination | simonw 9599 | open | 0 | 7 | 2020-09-21T00:14:37Z | 2020-09-21T02:55:54Z | MEMBER | Useful for #16 (timeline view) since you can now filter to just the items on a specific day - but if there are more than 50 items you can't see them all. | dogsheep-beta 197431109 | issue | {"url": "https://api.github.com/repos/dogsheep/dogsheep-beta/issues/26/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 705827457 | MDU6SXNzdWU3MDU4Mjc0NTc= | 971 | Support the dbstat table | simonw 9599 | closed | 0 | 7 | 2020-09-21T18:38:53Z | 2020-09-21T19:00:02Z | 2020-09-21T18:59:52Z | OWNER | `dbstat` is a table that is usually available on SQLite giving statistics about the database. For example: https://fivethirtyeight.datasettes.com/fivethirtyeight?sql=SELECT+*+FROM+%22dbstat%22+WHERE+name%3D%27bachelorette%2Fbachelorette%27%3B | name | path | pageno | pagetype | ncell | payload | unused | mx_payload | pgoffset | pgsize | |---------------------------|--------|----------|------------|---------|-----------|----------|--------------|------------|----------| | bachelorette/bachelorette | / | 89 | internal | 13 | 0 | 3981 | 0 | 360448 | 4096 | | bachelorette/bachelorette | /000/ | 91 | leaf | 66 | 3792 | 32 | 74 | 368640 | 4096 | | bachelorette/bachelorette | /001/ | 92 | leaf | 67 | 3800 | 14 | 74 | 372736 | 4096 | | bachelorette/bachelorette | /002/ | 93 | leaf | 65 | 3717 | 46 | 70 | 376832 | 4096 | | bachelorette/bachelorette | /003/ | 94 | leaf | 68 | 3742 | 6 | 71 | 380928 | 4096 | | bachelorette/bachelorette | /004/ | 95 | leaf | 70 | 3696 | 42 | 66 | 385024 | 4096 | | bachelorette/bachelorette | /005/ | 96 | leaf | 69 | 3721 | 22 | 71 | 389120 | 4096 | | bachelorette/bachelorette | /006/ | 97 | leaf | 70 | 3737 | 1 | 72 | 393216 | 4096 | | bachelorette/bachelorette | /007/ | 98 | leaf | 69 | 3728 | 15 | 69 | 397312 | 4096 | | bachelorette/bachelorette | /008/ | 99 | leaf | 73 | 3715 | 8 | 64 | 401408 | 4096 | | bachelorette/bachelorette | /009/ | 100 | leaf | 73 | 3705 | 18 | 62 | 405504 | 4096 | | bachelorette/bachelorette | /… | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/971/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 707944044 | MDExOlB1bGxSZXF1ZXN0NDkyMjU3NDA1 | 174 | Much, much faster extract() implementation | simonw 9599 | closed | 0 | 7 | 2020-09-24T07:52:31Z | 2020-09-24T15:44:00Z | 2020-09-24T15:43:56Z | OWNER | simonw/sqlite-utils/pulls/174 | Takes my test down from ten minutes to four seconds. Refs #172. | sqlite-utils 140912432 | pull | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/174/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 712984738 | MDU6SXNzdWU3MTI5ODQ3Mzg= | 987 | Documented HTML hooks for JavaScript plugin authors | simonw 9599 | open | 0 | 7 | 2020-10-01T16:10:14Z | 2021-01-25T04:00:03Z | OWNER | In #981 I added `data-column=` attributes to the `<th>` on the table page. These should become part of Datasette's documented API so JavaScript plugin authors can use them to derive things about the tables shown on a page (`datasette-cluster-map uses them as-of https://github.com/simonw/datasette-cluster-map/issues/18). | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/987/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 714377268 | MDU6SXNzdWU3MTQzNzcyNjg= | 991 | Redesign application homepage | simonw 9599 | open | 0 | 7 | 2020-10-04T18:48:45Z | 2021-01-26T19:06:36Z | OWNER | Most Datasette instances only host a single database, but the current homepage design assumes that it should leave plenty of space for multiple databases: <img width="878" alt="Datasette_Fixtures__fixtures" src="https://user-images.githubusercontent.com/9599/95024344-5b51fd80-0637-11eb-8a11-40bad16f6907.png"> Reconsider this design - should the default show more information? The Covid-19 Datasette homepage looks particularly sparse I think: https://covid-19.datasettes.com/ <img width="782" alt="COVID-19_cases__using_data_from_Johns_Hopkins_CSSE__the_New_York_Times_and_the_LA_Times__covid" src="https://user-images.githubusercontent.com/9599/95024391-876d7e80-0637-11eb-8f19-ef38e4c87d2a.png"> | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/991/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 721050815 | MDU6SXNzdWU3MjEwNTA4MTU= | 1019 | "Edit SQL" button on canned queries | jsfenfen 639012 | closed | 0 | 0.51 6026070 | 7 | 2020-10-14T00:51:39Z | 2020-10-23T19:44:06Z | 2020-10-14T03:44:23Z | CONTRIBUTOR | Feature request: Would it be possible to add an "edit this query" button on canned queries? Clicking it would open the canned query as an editable sql query. I think the intent is to have named parameters to allow this, but sometimes you just gotta rewrite it? | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1019/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 722724086 | MDU6SXNzdWU3MjI3MjQwODY= | 1025 | Fix last remaining links to "/" that do not respect base_url | simonw 9599 | closed | 0 | 0.51 6026070 | 7 | 2020-10-15T22:46:38Z | 2020-10-23T19:44:06Z | 2020-10-20T05:21:29Z | OWNER | Refs #1023 ``` datasette % git grep '"/"' -- '*.html' datasette/templates/error.html: <a href="/">home</a> datasette/templates/patterns.html: <a href="/">home</a> / datasette/templates/query.html: <a href="/">home</a> / ``` | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1025/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 722816436 | MDU6SXNzdWU3MjI4MTY0MzY= | 186 | .extract() shouldn't extract null values | simonw 9599 | open | 0 | 7 | 2020-10-16T02:41:08Z | 2021-08-12T12:32:14Z | OWNER | This almost works, but it creates a rogue `type` record with a value of None. ``` In [1]: import sqlite_utils In [2]: db = sqlite_utils.Database(memory=True) In [5]: db["creatures"].insert_all([ {"id": 1, "name": "Simon", "type": None}, {"id": 2, "name": "Natalie", "type": None}, {"id": 3, "name": "Cleo", "type": "dog"}], pk="id") Out[5]: <Table creatures (id, name, type)> In [7]: db["creatures"].extract("type") Out[7]: <Table creatures (id, name, type_id)> In [8]: list(db["creatures"].rows) Out[8]: [{'id': 1, 'name': 'Simon', 'type_id': None}, {'id': 2, 'name': 'Natalie', 'type_id': None}, {'id': 3, 'name': 'Cleo', 'type_id': 2}] In [9]: db["type"] Out[9]: <Table type (id, type)> In [10]: list(db["type"].rows) Out[10]: [{'id': 1, 'type': None}, {'id': 2, 'type': 'dog'}] ``` | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/186/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 723838331 | MDU6SXNzdWU3MjM4MzgzMzE= | 11 | export.xml file name varies with different language settings | jarib 572 | closed | 0 | 7 | 2020-10-17T20:07:18Z | 2020-10-17T21:39:15Z | 2020-10-17T21:14:10Z | NONE | The XML file exported from my phone has a Norwegian file name – `eksport.xml` 🙄 I can work around this by unpacking the zip and using `--xml`, but then I lose the workout points. Perhaps this could be solved by `--localized-xml eksport.xml`? Alternatively just fall back to the first XML file in the root folder of the zip. | healthkit-to-sqlite 197882382 | issue | {"url": "https://api.github.com/repos/dogsheep/healthkit-to-sqlite/issues/11/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 728905098 | MDU6SXNzdWU3Mjg5MDUwOTg= | 1048 | Documentation and unit tests for urls.row() urls.row_blob() methods | simonw 9599 | open | 0 | 7 | 2020-10-25T00:13:53Z | 2022-07-10T16:23:57Z | OWNER | https://github.com/simonw/datasette/blob/5db7ae3ce165ded57c7fb1cfbdb3258b1cf06c10/datasette/app.py#L1307-L1313 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1048/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 734777631 | MDU6SXNzdWU3MzQ3Nzc2MzE= | 1080 | "View all" option for facets, to provide a (paginated) list of ALL of the facet counts plus a link to view them | simonw 9599 | open | 0 | Datasette 1.0 3268330 | 7 | 2020-11-02T19:55:06Z | 2022-02-04T06:25:18Z | OWNER | Can use `/database/-/...` namespace from #296 | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1080/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | |||||||
| 743384829 | MDExOlB1bGxSZXF1ZXN0NTIxMjg3OTk0 | 203 | changes to allow for compound foreign keys | drkane 1049910 | open | 0 | 7 | 2020-11-16T00:30:10Z | 2023-01-25T18:47:18Z | FIRST_TIME_CONTRIBUTOR | simonw/sqlite-utils/pulls/203 | Add support for compound foreign keys, as per issue #117 Not sure if this is the right approach. In particular I'm unsure about: - the new `ForeignKey` class, which replaces the namedtuple in order to ensure that `column` and `other_column` are forced into tuples. The class does the job, but doesn't feel very elegant. - I haven't rewritten `guess_foreign_table` to take account of multiple columns, so it just checks for the first column in the foreign key definition. This isn't ideal. - I haven't added any ability to the CLI to add compound foreign keys, it's only in the python API at the moment. The PR also contains a minor related change that columns and tables are always quoted in foreign key definitions. | sqlite-utils 140912432 | pull | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/203/reactions", "total_count": 1, "+1": 0, "-1": 0, "laugh": 0, "hooray": 1, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | ||||||
| 816560819 | MDU6SXNzdWU4MTY1NjA4MTk= | 240 | table.pks_and_rows_where() method returning primary keys along with the rows | simonw 9599 | closed | 0 | 7 | 2021-02-25T15:49:28Z | 2021-02-25T16:39:23Z | 2021-02-25T16:28:23Z | OWNER | *Original title: Easier way to update a row returned from .rows* Here's a surprisingly hard problem I ran into while trying to implement #239 - given a row returned by `db[table].rows` how can you update that row? The problem is that the `db[table].update(...)` method requires a primary key. But if you have a row from the `db[table].rows` iterator it might not even contain the primary key - provided the table is a `rowid` table. Instead, currently, you need to introspect the table and, if `rowid` is a primary key, explicitly include that in the `select=` argument to `table.rows_where(...)` - otherwise it will not be returned. A utility mechanism to make this easier would be very welcome. | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/240/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 841456306 | MDU6SXNzdWU4NDE0NTYzMDY= | 1276 | Invalid SQL: "no such table: pragma_database_list" on database page | justinallen 1314318 | closed | 0 | 7 | 2021-03-26T00:03:53Z | 2021-03-31T16:27:27Z | 2021-03-28T23:52:31Z | NONE | Don't think this has been covered here yet. I'm a little stumped with this one and can't tell if it's a bug or I have something misconfigured. Oddly, when running locally the usual list of tables populates (i.e. at /charts a list of tables in charts.db). But when on the web server it throws an Invalid SQL error and "no such table: pragma_database_list" below. All the url endpoints seem to work fine aside from this - individual tables (/charts/chart_one), as well as stored queries (/charts/query_one). Not sure if this has anything to do with upgrading to Datasette 0.55, or something to do with our setup, which uses a metadata build script similar to [the one for the 538 server](https://github.com/simonw/fivethirtyeight-datasette/blob/main/make_metadata.py), or something else. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1276/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 842881221 | MDU6SXNzdWU4NDI4ODEyMjE= | 1281 | Latest Datasette tags missing from Docker Hub | simonw 9599 | closed | 0 | 7 | 2021-03-29T00:58:30Z | 2021-03-29T01:41:48Z | 2021-03-29T01:41:48Z | OWNER | Spotted this while testing https://github.com/simonw/datasette/issues/1249#issuecomment-808998719_ https://hub.docker.com/r/datasetteproject/datasette/tags?page=1&ordering=last_updated isn't showing the tags for any version more recent than 0.54.1 - we are up to 0.56 now. But the `:latest` tag is for the new 0.56 release. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1281/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 898904402 | MDU6SXNzdWU4OTg5MDQ0MDI= | 1337 | "More" link for facets that shows _facet_size=max results | simonw 9599 | closed | 0 | 7 | 2021-05-23T00:08:51Z | 2021-05-27T16:14:14Z | 2021-05-27T16:01:03Z | OWNER | _Original title: "More" link for facets that shows the full set of results_ The simplest way to do this will be to have it link to a generated SQL query. _Originally posted by @simonw in https://github.com/simonw/datasette/issues/1332#issuecomment-846479062_ | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1337/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 904071938 | MDU6SXNzdWU5MDQwNzE5Mzg= | 1345 | ?_nocol= does not interact well with default facets | simonw 9599 | closed | 0 | 7 | 2021-05-27T18:39:55Z | 2021-05-31T02:40:44Z | 2021-05-31T02:31:21Z | OWNER | Clicking "Hide this column" on `fips` on https://covid-19.datasettes.com/covid/ny_times_us_counties shows this error: https://covid-19.datasettes.com/covid/ny_times_us_counties?_nocol=fips > ## Invalid SQL > no such column: fips The reason is that https://covid-19.datasettes.com/-/metadata sets up the following: ```json "ny_times_us_counties": { "sort_desc": "date", "facets": [ "state", "county", "fips" ], ``` It's setting `fips` as a default facet, which breaks if you attempt to remove the column using `?_nocol`. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1345/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 924990677 | MDU6SXNzdWU5MjQ5OTA2Nzc= | 279 | sqlite-utils memory should handle TSV and JSON in addition to CSV | simonw 9599 | closed | 0 | 7 | 2021-06-18T15:02:54Z | 2021-06-19T03:11:59Z | 2021-06-19T03:11:59Z | OWNER | - Use sniff to detect CSV or TSV (if `:tsv` or `:csv` was not specified) and delimiters Follow-on from #272 | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/279/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 925410305 | MDU6SXNzdWU5MjU0MTAzMDU= | 285 | Introspection property for telling if a table is a rowid table | simonw 9599 | closed | 0 | 7 | 2021-06-19T14:56:16Z | 2021-06-19T15:12:33Z | 2021-06-19T15:12:33Z | OWNER | _Originally posted by @simonw in https://github.com/simonw/sqlite-utils/issues/284#issuecomment-864416785_ | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/285/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 972918533 | MDU6SXNzdWU5NzI5MTg1MzM= | 1438 | Query page .csv and .json links are not correctly URL-encoded on Vercel under unknown specific conditions | simonw 9599 | open | 0 | 7 | 2021-08-17T17:35:36Z | 2021-08-18T00:22:23Z | OWNER | > Confirmed: https://thesession.vercel.app/thesession?sql=select+*+from+tunes+where+name+like+%22%25wise+maid%25%22%0D%0A is a page where the URL correctly encoded `%` as `%25` - but then in the HTML on that page that links to the CSV and JSON versions we get this: > > ```html > <p class="export-links">This data as > <a href="/thesession.json?sql=select * from tunes where name like "%wise maid%"">json</a>, > <a href="/thesession.csv?sql=select * from tunes where name like "%wise maid%"&_size=max">CSV</a> > </p> > ``` Those CSV and JSON links are incorrect. _Originally posted by @simonw in https://github.com/simonw/datasette-publish-vercel/issues/48#issuecomment-900497579_ | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1438/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 1055402144 | PR_kwDOBm6k_c4unfnq | 1512 | New pattern for async view classes | simonw 9599 | closed | 0 | 7 | 2021-11-16T21:55:44Z | 2021-11-17T01:39:54Z | 2021-11-17T01:39:44Z | OWNER | simonw/datasette/pulls/1512 | Refs #878 - starting out with the new `AsyncBase` class implementing a pytest-inspired `asyncio` parallel execution mechanism. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/1512/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 1 | |||||
| 1058196641 | I_kwDOCGYnMM4_Esyh | 342 | Extra options to `lookup()` which get passed to `insert()` | simonw 9599 | closed | 0 | 7 | 2021-11-19T06:53:03Z | 2021-11-19T07:26:54Z | 2021-11-19T07:26:54Z | OWNER | For https://github.com/simonw/git-history/issues/12 I found myself wanting to pass extra options to `lookup()` to set the column order, primary key etc. | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/342/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1059555791 | I_kwDOBm6k_c4_J4nP | 1527 | Columns starting with an underscore behave poorly in filters | simonw 9599 | closed | 0 | Datasette 0.60 7571612 | 7 | 2021-11-22T01:01:36Z | 2022-01-14T00:57:08Z | 2022-01-14T00:57:08Z | OWNER | Similar bug to #1525 (and #1506 before it). Start on https://latest.datasette.io/fixtures/facetable?_facet=_neighborhood - then select a neighborhood - then try to remove that filter using the little "x" and submitting the form again.  | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1527/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 1077243232 | I_kwDOCGYnMM5ANW1g | 354 | Test failure in test_rebuild_fts | simonw 9599 | closed | 0 | 7 | 2021-12-10T21:27:55Z | 2021-12-11T01:08:46Z | 2021-12-11T01:08:46Z | OWNER | Not sure why this has only just started failing, but I'm getting this: https://github.com/simonw/sqlite-utils/runs/4488687639 ``` E sqlite3.DatabaseError: database disk image is malformed sqlite_utils/db.py:425: DatabaseError _______________________ test_rebuild_fts[searchable_fts] _______________________ fresh_db = <Database <sqlite3.Connection object at 0x1084ea9d0>> table_to_fix = 'searchable_fts' @pytest.mark.parametrize("table_to_fix", ["searchable", "searchable_fts"]) def test_rebuild_fts(fresh_db, table_to_fix): table = fresh_db["searchable"] table.insert(search_records[0]) table.enable_fts(["text", "country"]) # Run a search rows = list(table.search("tanuki")) assert len(rows) == 1 assert { "rowid": 1, "text": "tanuki are running tricksters", "country": "Japan", "not_searchable": "foo", }.items() <= rows[0].items() # Delete from searchable_fts_data fresh_db["searchable_fts_data"].delete_where() # This should have broken the index with pytest.raises(sqlite3.DatabaseError): list(table.search("tanuki")) # Running rebuild_fts() should fix it > fresh_db[table_to_fix].rebuild_fts() ``` | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/354/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1082651698 | I_kwDOCGYnMM5Ah_Qy | 358 | Support for CHECK constraints | luxint 11597658 | open | 0 | 7 | 2021-12-16T21:19:45Z | 2022-09-25T07:15:59Z | NONE | Hi, I noticed the `transform.table()` method doesn't have an option to add/change or drop a check constraint (see https://sqlite.org/lang_createtable.html -> 3.7 Check Constraints. would be great to have this as an option! | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/358/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 1087931918 | I_kwDOBm6k_c5A2IYO | 1579 | `.execute_write(... block=True)` should be the default behaviour | simonw 9599 | closed | 0 | Datasette 0.60 7571612 | 7 | 2021-12-23T18:54:28Z | 2022-01-13T22:28:08Z | 2021-12-23T19:18:26Z | OWNER | Every single piece of code I've written against the write APIs has used the `block=True` option to wait for the result. Without that, it instead fires the write into the queue but then continues even before it has finished executing. `block=True` should clearly be the default behaviour here! | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1579/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | |||||
| 1100015398 | I_kwDOBm6k_c5BkOcm | 1591 | Maybe let plugins define custom serve options? | simonw 9599 | open | 0 | 7 | 2022-01-12T08:18:47Z | 2022-01-15T11:56:59Z | OWNER | https://twitter.com/psychemedia/status/1481171650934714370 > can extensions be passed their own cli args? eg `--ext-tiddlywiki-dbname tiddlywiki2.sqlite` ? I've thought something like this might be useful for other plugins in the past, too. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1591/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 1114543475 | I_kwDOCGYnMM5CbpVz | 388 | Link to stable docs from older versions | simonw 9599 | closed | 0 | 7 | 2022-01-26T01:55:46Z | 2023-03-26T23:43:12Z | 2022-01-26T02:00:22Z | OWNER | https://sqlite-utils.datasette.io/en/2.14.1/ isn't showing a link to the stable release right now. I should also apply the same fix I used for Datasette in: - https://github.com/simonw/datasette/issues/1608 TIL: https://til.simonwillison.net/readthedocs/link-from-latest-to-stable | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/388/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1138948786 | PR_kwDOCGYnMM4y3yW0 | 407 | Add SpatiaLite helpers to CLI | eyeseast 25778 | closed | 0 | 7 | 2022-02-15T16:50:17Z | 2022-02-16T01:49:40Z | 2022-02-16T00:58:08Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/407 | Closes #398 This adds SpatiaLite helpers to the CLI. ```sh # init spatialite when creating a database sqlite-utils create database.db --enable-wal --init-spatialite # add geometry columns # needs a database, table, geometry column name, type, with optional SRID and not-null # this will throw an error if the table doesn't already exist sqlite-utils add-geometry-column database.db table-name geometry --srid 4326 --not-null # spatial index an existing table/column # this will throw an error it the table and column don't exist sqlite-utils create-spatial-index database.db table-name geometry ``` Docs and tests are included. | sqlite-utils 140912432 | pull | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/407/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 1160432941 | PR_kwDOBm6k_c4z_p6S | 1648 | Use dash encoding for table names and row primary keys in URLs | simonw 9599 | closed | 0 | 7 | 2022-03-05T19:50:45Z | 2022-03-07T15:38:30Z | 2022-03-07T15:38:30Z | OWNER | simonw/datasette/pulls/1648 | Refs #1439. - [x] Build `dash_encode` / `dash_decode` functions - [x] Use dash encoding for row primary keys - [x] Use dash encoding for `?_next=` pagination tokens - [x] Use dash encoding for table names in URLs - [x] Use dash encoding for database name - ~~Implement redirects from previous `%` URLs that replace those with `-`~~ - separate issue: #1650 | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/1648/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 1166731361 | I_kwDOCGYnMM5Fiuhh | 414 | I forgot to include the changelog in the 3.25.1 release | simonw 9599 | closed | 0 | 7 | 2022-03-11T18:32:36Z | 2022-03-11T18:40:39Z | 2022-03-11T18:40:39Z | OWNER | I pushed a release for https://github.com/simonw/sqlite-utils/releases/tag/3.25.1 but forgot to include the release notes in `docs/changelog.rst` This means https://sqlite-utils.datasette.io/en/stable/changelog.html isn't showing them. | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/414/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1173017980 | PR_kwDOBm6k_c40oRq- | 1664 | Remove hashed URL mode | simonw 9599 | closed | 0 | 7 | 2022-03-17T23:19:10Z | 2022-03-19T00:12:04Z | 2022-03-19T00:12:04Z | OWNER | simonw/datasette/pulls/1664 | Refs #1661. | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/1664/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 1175648453 | I_kwDOBm6k_c5GEvjF | 1675 | Extract out `check_permissions()` from `BaseView | simonw 9599 | closed | 0 | 7 | 2022-03-21T16:39:46Z | 2022-03-21T17:14:31Z | 2022-03-21T17:13:21Z | OWNER | > I'm going to refactor this stuff out and document it so it can be easily used by plugins: https://github.com/simonw/datasette/blob/4a4164b81191dec35e423486a208b05a9edc65e4/datasette/views/base.py#L69-L103 _Originally posted by @simonw in https://github.com/simonw/datasette/issues/1660#issuecomment-1074136176_ | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1675/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1239008850 | I_kwDOBm6k_c5J2cZS | 1744 | `--nolock` feature for opening locked databases | simonw 9599 | closed | 0 | 7 | 2022-05-17T18:25:16Z | 2022-05-17T19:46:38Z | 2022-05-17T19:40:30Z | OWNER | The getting started docs currently suggest you try this to browse your Chrome history: datasette ~/Library/Application\ Support/Google/Chrome/Default/History But if Chrome is running you will likely get this error: sqlite3.OperationalError: database is locked Turns out there's a workaround for this which I just spotted [on the SQLite forum](https://sqlite.org/forum/forumpost/86a67f6995): > You can do this using a [URI filename](https://sqlite.org/uri.html): > ``` > sqlite3 'file:places.sqlite?mode=ro&nolock=1' > ``` > That opens the file `places.sqlite` in read-only mode with locking disabled. This isn't safe, in that changes to the database made by other corrections are likely to cause this connection to return incorrect results or crash. Read-only mode should at least mean that you don't corrupt the database in the process. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1744/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1239034903 | I_kwDOCGYnMM5J2iwX | 433 | CLI eats my cursor | chapmanjacobd 7908073 | open | 0 | 7 | 2022-05-17T18:52:52Z | 2023-07-18T19:08:50Z | CONTRIBUTOR | I'm not sure why this happens but `sqlite-utils` makes my terminal cursor disappear after running commands like `sqlite-utils insert`. I've only noticed this behavior in `sqlite-utils`. Not sure if it is a bug in `kitty`, `fish` or `sqlite-utils` I can still type commands after it runs but the text cursor is invisible | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/433/reactions", "total_count": 4, "+1": 4, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 1363552780 | I_kwDOBm6k_c5RRioM | 1805 | truncate_cells_html does not work for links? | CharlesNepote 562352 | open | 0 | 7 | 2022-09-06T16:41:29Z | 2022-10-03T09:18:06Z | NONE | We have many links inside our dataset (please don't blame us ;-). When I use `--settings truncate_cells_html 60` it is not working for the links. Eg. https://images.openfoodfacts.org/images/products/000/000/000/088/nutrition_fr.5.200.jpg (87 chars) is not truncated:  IMHO It would make sense that links should be treated as HTML. The link should work of course, but Datasette could truncate it: [https://images.openfoodfacts.org/images/products/00[...].jpg](https://images.openfoodfacts.org/images/products/000/000/000/088/nutrition_fr.5.200.jpg) | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1805/reactions", "total_count": 1, "+1": 1, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | reopened | |||||||
| 1366512990 | PR_kwDOCGYnMM4-nBs9 | 486 | progressbar for inserts/upserts of all fileformats, closes #485 | MischaU8 99098079 | closed | 0 | 7 | 2022-09-08T14:58:02Z | 2022-09-15T20:40:03Z | 2022-09-15T20:37:51Z | CONTRIBUTOR | simonw/sqlite-utils/pulls/486 | <!-- readthedocs-preview sqlite-utils start --> ---- :books: Documentation preview :books:: https://sqlite-utils--486.org.readthedocs.build/en/486/ <!-- readthedocs-preview sqlite-utils end --> | sqlite-utils 140912432 | pull | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/486/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 0 | |||||
| 1383646615 | I_kwDOCGYnMM5SeMWX | 491 | Ability to merge databases and tables | sgraaf 8904453 | open | 0 | 7 | 2022-09-23T11:10:55Z | 2023-06-14T22:14:24Z | NONE | Hi! Let me firstly say that I am a big fan of your work -- I follow your tweets and blog posts with great interest 😄. Now onto the matter at hand: I think it would be great if `sqlite-utils` included a `merge` or `combine` command, with the purpose of combining different SQLite databases into a single SQLite database. This way, the newly "merged" database would contain all differently named tables contained in the databases to be merged as-is, as well a concatenation of all tables of the same name. This could look something like this: ```bash sqlite-utils merge cats.db dogs.db > animals.db ``` I imagine this is rather straightforward if all databases involved in the merge contain differently named tables (i.e. no chance of conflicts), but things get slightly more complicated if two or more of the databases to be merged contain tables with the same name. Not only do you have to "do something" with the primary key(s), but these tables could also simply have different schemas (and therefore be incompatible for concatenation to begin with). Anyhow, I would love your thoughts on this, and, if you are open to it, work together on the design and implementation! | sqlite-utils 140912432 | issue | {"url": "https://api.github.com/repos/simonw/sqlite-utils/issues/491/reactions", "total_count": 1, "+1": 1, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 1384273985 | I_kwDOBm6k_c5SglhB | 1817 | Expose `sql` and `params` arguments to various plugin hooks | simonw 9599 | open | 0 | 7 | 2022-09-23T20:34:45Z | 2022-09-27T00:27:53Z | OWNER | On Discord: https://discord.com/channels/823971286308356157/996877076982415491/1022784534363787305 > Hi! I'm attempting to write a plugin that would provide some statistics on text fields (most common words, etc). I would want this information displayed in the table pages, and (ideally) also updated when users make custom queries from the table pages. > > It seems one way to do this would be to use the extra_template_vars hook, and make the appropriate SQL query there. So extra_template_vars would create a variable that is a list of most common words, and this is displayed on the page, possibly above the regular table view. > > Is there a way that the plugin code can access the SQL query (or even the data) that was used to produce the table view? I can see that TableView class constructs the SQL query, but I can't seem to find a way to access that information from the objects that are available to extra_template_vars. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1817/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 1422915587 | I_kwDOBm6k_c5Uz_gD | 1853 | Upgrade Datasette Docker to Python 3.11 | simonw 9599 | closed | 0 | 7 | 2022-10-25T18:44:31Z | 2022-10-25T19:28:56Z | 2022-10-25T19:05:16Z | OWNER | Related: - #1768 I think this base image looks right: [3.11.0-slim-bullseye](https://hub.docker.com/layers/library/python/3.11.0-slim-bullseye/images/sha256-244c0b0e6e7608a16f87382fc8a5ef3c330d042113a9a7b6fc15a95360181651?context=explore) | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1853/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1430797211 | I_kwDOBm6k_c5VSDub | 1875 | Figure out design for JSON errors (consider RFC 7807) | simonw 9599 | open | 0 | Datasette 1.0a3 8755003 | 7 | 2022-11-01T03:14:15Z | 2022-12-13T05:29:08Z | OWNER | https://datatracker.ietf.org/doc/draft-ietf-httpapi-rfc7807bis/ is a brand new standard. Since I need a neat, predictable format for my JSON errors, maybe I should use this one? | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1875/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | |||||||
| 1473481262 | I_kwDOBm6k_c5X04ou | 1928 | Hacker News Datasette write demo | simonw 9599 | closed | 0 | 7 | 2022-12-02T21:17:41Z | 2022-12-02T23:47:11Z | 2022-12-02T21:43:19Z | OWNER | Idea is to have my existing scraper at https://github.com/simonw/scrape-hacker-news-by-domain also write to my private Datasette Cloud account, then create an atom feed from it. | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/1928/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1616354999 | I_kwDOJHON9s5gV563 | 2 | First working version | simonw 9599 | closed | 0 | 7 | 2023-03-09T03:53:00Z | 2023-03-09T05:10:22Z | 2023-03-09T05:10:22Z | MEMBER | It's going to shell out to `osascript` as seen in: - #1 I'm going with that option because https://appscript.sourceforge.io/status.html warns against the other potential methods: > Apple eliminated its Mac Automation department in 2016. The future of AppleScript and its related technologies is unclear. Caveat emptor. But `osascript` looks pretty stable to me. | apple-notes-to-sqlite 611552758 | issue | {"url": "https://api.github.com/repos/dogsheep/apple-notes-to-sqlite/issues/2/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | completed | ||||||
| 1656432059 | PR_kwDOBm6k_c5NuBNG | 2053 | WIP new JSON for queries | simonw 9599 | open | 0 | 7 | 2023-04-05T23:26:15Z | 2023-05-26T23:13:03Z | OWNER | simonw/datasette/pulls/2053 | Refs: - #2049 TODO: - [x] Read queries JSON - [ ] Implement error display with `"ok": false` and an errors key - [ ] Read queries HTML - [ ] Read queries other formats (plugins) - [ ] Canned read queries (dispatched to from table) - [ ] Write queries (a canned query thing) - [ ] Implement different shapes, refactoring to share code with table - [ ] Implement a sensible subset of extras, also refactoring to share code with table - [ ] Get all tests passing <!-- readthedocs-preview datasette start --> ---- :books: Documentation preview :books:: https://datasette--2053.org.readthedocs.build/en/2053/ <!-- readthedocs-preview datasette end --> | datasette 107914493 | pull | {"url": "https://api.github.com/repos/simonw/datasette/issues/2053/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | 1 | ||||||
| 1781530343 | I_kwDOBm6k_c5qL_7n | 2093 | Proposal: Combine settings, metadata, static, etc. into a single `datasette.toml` File | asg017 15178711 | open | 0 | 7 | 2023-06-29T21:18:23Z | 2023-07-02T02:17:47Z | CONTRIBUTOR | Very often I get tripped up when trying to configure my Datasette instances. For example: if I want to change the port my app listen too, do I do that with a CLI flag, a `--setting` flag, inside `metadata.json`, or an env var? If I want to up the time limit of SQL statements, is that under `metadata.json` or a setting? Where does my plugin configuration go? Normally I need to look it up in Datasette docs, and I quickly find my answer, but the number of places where "config" goes it overwhelming. - Flat CLI flags like `--port`, `--host`, `--cors`, etc. - `--setting`, like `default_page_size`, `sql_time_limit_ms` etc - Inside `metadata.json`, including plugin configuration Typically my Datasette deploys are extremely long shell commands, with multiple `--setting` and other CLI flags. ## Proposal: Consolidate all "config" into `datasette.toml` I propose that we add a new `datasette.toml` that combines "settings", "metadata", and other common CLI flags like `--port` and `--cors` into a single file. It would be similar to "Cargo.toml" in Rust projects, "package.json" in Node projects, and "pyproject.toml" in Python, etc. A sample of what it could look like: ```toml # "top level" configuration that are currently CLI flags on `datasette serve` [config] port = 8020 host = "0.0.0.0" cors = true # replaces multiple `--setting` flags [settings] base_url = "/app/datasette/" default_allow_sql = true sql_time_limit_ms = 3500 # replaces `metadata.json`. # The contents of datasette-metadata.json could be defined in this file instead, but supporting separate files is nice (since those are easy to machine-generate) [metadata] include="./datasette-metadata.json" # plugin-specific [plugins] [plugins.datasette-auth-github] client_id = {env = "DATASETTE_AUTH_GITHUB_CLIENT_ID"} client_secret = {env = "GITHUB_CLIENT_SECRET"} [plugins.datasette-cluster-map] latitude_column = "lat" longitude_column = "lon" ``` ## Pros - Instead of multiple files and CLI flags, everything could b… | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/2093/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} | ||||||||
| 1805076818 | I_kwDOBm6k_c5rl0lS | 2102 | API tokens with view-table but not view-database/view-instance cannot access the table | simonw 9599 | open | 0 | 7 | 2023-07-14T15:34:27Z | 2023-07-18T11:47:21Z | OWNER | > Spotted a problem while working on this: if you grant a token access to view table for a specific table but don't also grant view database and view instance permissions, that token is useless. > > This was a deliberate design decision in Datasette - it's documented on https://docs.datasette.io/en/1.0a2/authentication.html#access-permissions-in-metadata > >> If a user cannot access a specific database, they will not be able to access tables, views or queries within that database. If a user cannot access the instance they will not be able to access any of the databases, tables, views or queries. > > I'm now second-guessing if this was a good decision. _Originally posted by @simonw in https://github.com/simonw/datasette-auth-tokens/issues/7#issuecomment-1636031702_ | datasette 107914493 | issue | {"url": "https://api.github.com/repos/simonw/datasette/issues/2102/reactions", "total_count": 0, "+1": 0, "-1": 0, "laugh": 0, "hooray": 0, "confused": 0, "heart": 0, "rocket": 0, "eyes": 0} |
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issues] (
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[number] INTEGER,
[title] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[state] TEXT,
[locked] INTEGER,
[assignee] INTEGER REFERENCES [users]([id]),
[milestone] INTEGER REFERENCES [milestones]([id]),
[comments] INTEGER,
[created_at] TEXT,
[updated_at] TEXT,
[closed_at] TEXT,
[author_association] TEXT,
[pull_request] TEXT,
[body] TEXT,
[repo] INTEGER REFERENCES [repos]([id]),
[type] TEXT
, [active_lock_reason] TEXT, [performed_via_github_app] TEXT, [reactions] TEXT, [draft] INTEGER, [state_reason] TEXT);
CREATE INDEX [idx_issues_repo]
ON [issues] ([repo]);
CREATE INDEX [idx_issues_milestone]
ON [issues] ([milestone]);
CREATE INDEX [idx_issues_assignee]
ON [issues] ([assignee]);
CREATE INDEX [idx_issues_user]
ON [issues] ([user]);